
| z, ? | toggle help (this) |
| space, → | next slide |
| shift-space, ← | previous slide |
| d | toggle debug mode |
| ## <ret> | go to slide # |
| r | reload slides |
| n | toggle notes |
Hello everyone. It is an honor to be able to present to RubyConf Pakistan. My presentation today is on Roda, Ruby’s fourth most popular web framework. Roda was released back in 2014, so it is almost 8 years old now.|Roda is focused on 4 goals: simplicity, reliability, extensibility, and performance. In this presentation, I will go into more detail on how Roda achieves these goals, and why you may want to use it in your applications.
My name is Jeremy Evans. I am a Ruby committer, and most of my work on Ruby itself is related to fixing bugs submitted on Ruby’s bug tracker. I am also a committer to Rack, the library that all Ruby web frameworks build on top of.|I develop and maintain many Ruby libraries in addition to Roda, such as Sequel, Ruby’s most advanced database library, and Rodauth, Ruby’s most advanced authentication framework.|In addition to that, I am a committer to OpenBSD, the security focused operating system, focusing on maintaining the Ruby ecosystem on OpenBSD.

I am also the author of Polished Ruby Programming, which was published last year. This book is aimed at intermediate Ruby programmers and focuses on teaching principles of Ruby programming, as well as trade-offs to consider when making implementation decisions.

Earlier I called Roda a web framework, but that’s mostly because it competes against other web frameworks that you are probably familiar with, such as Rails and Sinatra. I usually refer to Roda as a web toolkit, for reasons I will explain later in the presentation.
What differentiates Roda from most other Ruby web frameworks is that it is based on the concept of a routing tree built out of Ruby blocks, integrating routing with request handling. The use of a routing tree offers multiple advantages compared to routing approaches used by other Ruby web frameworks, which I will be discussing later in the presentation.
Since RubyConf Pakistan is a community of Ruby on Rails engineers and enthusiasts, I am going to assume most of you are familiar with Rails. Not having used Rails myself for new projects since 2008, and not having used it at all since 2014, I am not that familiar with modern Rails routing, but here are some examples from the Rails documentation.|Rails takes all of your routing code and compiles your routes into a deterministic finite automata engine, so that when requests are submitted, the correct Rails controller action will be dispatched to. You have no control over what happens during routing, beyond the routing configuration methods that Rails offers.
Rails.application.routes.draw do
resources :photos, :books
namespace :admin do
resources :brands, only: [:index, :show] do
resources :products, only: [:index, :show]
end
end
get '/patients/:id', to: 'patients#show'
resource :geocoder
end
Hopefully many of you are familiar with Sinatra, Ruby’s second most popular web framework. Sinatra’s main advantage over Rails is that it is much simpler. You directly specify all of your routes, along with a block to handle each route. All routes are stored in an array, and when a request comes in, Sinatra will iterate over the array of routes, and if the route matches the request, it will dispatch to the appropriate block. Like Rails, Sinatra offers you no control during the routing process.|Unfortunately, Sinatra’s simple routing approach comes at a significant cost to scalability. The more routes you add to your application, the longer routing takes for your application. So while routing in a small Sinatra application is generally faster than in a small Rails application, routing in a large Sinatra application will generally be slower than in a large Rails application. This is one reason you do not see many large Sinatra applications.
get '/' do
#
end
post '/brand/:brand_id/product/:product_id' do
#
end
get /\/hello\/([\w]+)/ do
#
end
get '/geocoder', :provides => ['rss', 'atom', 'xml'] do
#
end
Roda takes different approach to routing than other Ruby web frameworks. It uses a tree made out of nested Ruby blocks to route and handle requests.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
You use the Roda’s route method to set the routing tree for the application.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
All requests to the web application are yielded to the routing tree block. Roda’s convention is to use r as the name for the route block variable. Unlike Rails and Sinatra, where you do not have control over the details of the routing process, with Roda, you fully control how routing happens.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
You control routing by calling methods on the request object. The r.on method will yield to the block if all of the arguments passed to the method, called matchers, match the request. So if the current request starts with /foo, this method call will not match, and routing will continue after the method. However, if the current request starts with /album/ followed by some number, this method call will match, and the block passed to the method will be called.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
Because the Integer class was used as a matcher, if the method call matches, the number will be yielded to the block, as an integer. This makes it simple to extract data from the request path, instead of having to reference into a hash of params.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
This is the line that shows the true power of Roda. At any point during routing, since you are writing the routing code, you can implement your own behavior. In this case, we are using the integer taken from the request path, and trying to find a matching album. If we find the album, we set the album instance variable, which all routes inside this branch can use. If we do not find the album, then the code will call next, which will return from the block, and result in a 404 error page.|This ability to share logic and perform arbitrary actions at any point during routing is what makes Roda applications significantly simpler than web applications written in other frameworks.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
Assume the number from the request path resulted in a matching album. In that case, routing continues. The next method called is r.is, which will only match if the all matchers provided match, and the request path has been fully consumed after all matchers have matched. In this case, no matchers are provided, which means this will only match if the request path has already been completely consumed. So this block will be matched for requests such as /albums/1, but not /albums/1/tracks.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
Assuming the r.is method matched, the block passed to it will be called. Inside that block, we have calls to r.get and r.post. r.get will yield if the request method is GET, and r.post will yield if the request method is POST. Inside the r.get and r.post blocks are where you would put the code to handle the related routes.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
In both the r.get and r.post blocks, you do not have to worry about retrieving the related album, since the earlier code already retrieved it for you.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
Assume the request path is /albums/1/tracks. In that case, the r.is method call will not match, since the request path was not fully consumed by the time r.is was called. As I mentioned, in that case, r.is does not yield to the block, it just returns without doing anything.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
In that case, routing will continue to the next statement, r.get with an argument of tracks. When you call r.get with an argument, in addition to matching only if the request method is GET, it treats all arguments similar to r.is, only matching if all arguments match and the request path has been fully consumed by the end of matching.|So if the request path is /albums/1/tracks, and the request method is GET, this will match, because the /albums/1 part of the path had already been matched by the r.on call, and the r.get method call will match the remaining /tracks.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
Hopefully that gives you a flavor for how routing works in Roda.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
The most important part to remember is that Roda gives you the ability to run arbitrary code at any point during the routing process. It is hard to express how powerful this is, and how much simpler it can make code, but I will attempt to give some examples later in this presentation.
route do |r|
r.on "album", Integer do |album_id| # /albums/:id branch
next unless @album = Album[album_id]
r.is do # /albums/:id route
r.get do # GET /albums/:id route
end
r.post do # POST /albums/:id route
end
end
r.get "tracks" do # GET /albums/:id/tracks route
end
end
end
I cannot take credit for the routing tree idea, though I am the one that came up with the term routing tree. The idea of routing using nested Ruby blocks comes from Rum, a library by the original author of Rack, which was never released as a gem. The idea was later used and refined by Cuba, another web framework for Ruby. Roda is a fork of Cuba that keeps the same general approach of routing using a tree of Ruby blocks, but significantly improves performance and allows for easier extensibility.
I mentioned that Roda focuses on simplicity, reliability, extensibility, and performance. Of these, performance is the most objective advantage, in that you can directly compare the performance difference between Roda, Rails, and other web frameworks. Roda’s performance is actually much closer to web frameworks written in faster programming languages than it is to Rails.
According to one of the more well known web framework benchmarks by Tech Empower, proportionally there is about as much difference in performance between Rails and Roda as there is between Roda and the fastest known web framework, which is written in C++.
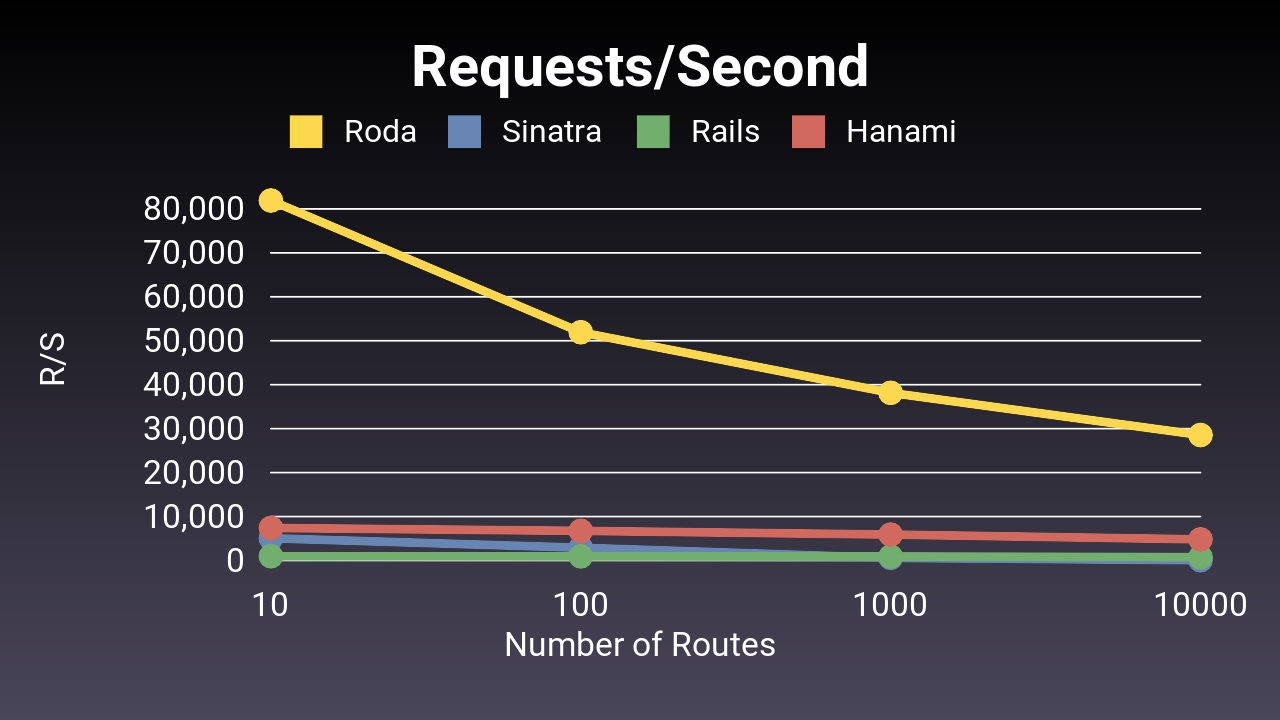
Tech Empower’s benchmarks are more general and do not specifically focus on performance for large numbers of routes. However, since I specifically wanted to make sure that Roda’s approach scales to large number of routes, I wrote a benchmark specifically for that.
The benchmark is called r10k, and it benchmarks Ruby web frameworks using 10, 100, 1000, and 10,000 routes. The purpose of r10k is to check web frameworks for routing scalability, to see if the still perform well as the number of routes increases.
r10k is open source on my GitHub, and I welcome external review to make sure I am not doing anything stupid or unfair to the other web frameworks. r10k has seen contributions from a handful of other Rubyists, including the author of Hanami.
Here are the runtime results for Roda, Sinatra, Rails, and Hanami. Pay no attention to the absolute numbers, as it is only the relative performance differences that matter. One thing to note about these numbers is that r10k benchmarks using the Rack API directly, so this does not include the web server overhead.|From this graph, you can see that Roda is much faster, starting around 80,000 requests per second and ending about 28,000 requests per second. However, it is kind of hard to see how much faster, since the scale of the graph makes Sinatra and Rails appear close to 0. Rails performance decreases slowly, from a little under 1000 requests per second at 10 routes to about 750 requests per second at 10000 routes. Sinatra’s performance takes a nosedive, from about 5000 requests per second at 10 routes, to about 60 requests per second at 10000 routes. Hanami’s performance is significantly better than Rails and Sinatra, varying between 7500 and 4800 requests per second, but still far behind Roda.
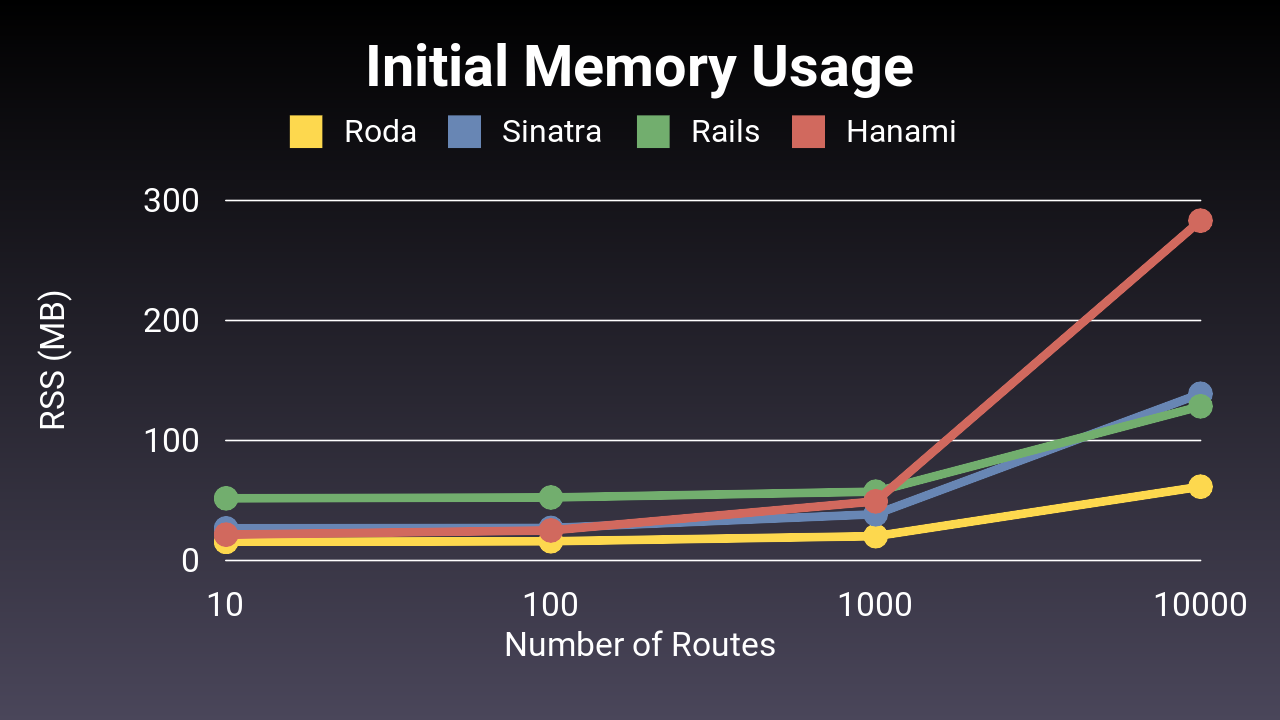
Another aspect of performance is memory usage, since Ruby applications are often more limited by memory than by processor usage. Roda always uses the least amount of memory, and at 10,000 routes, Roda uses about half of the memory compared to Rails and Sinatra. So if your application is memory bound and not processor bound, you may be able to run more Roda processes in the same amount of memory to offer higher performance.
Now that I have discussed Roda’s performance advantages, let me discuss Roda’s approach to simplicity. In general, Roda tries to be simple, in two ways. First, it tries to be simple internally, so that it is easy to understand and modify.
In other words, Roda tries to keep its implementation complexity low. You can compare the internal complexity to Sinatra and Rails, to see the differences.
Sinatra stores routes in an array, and iterates over the array of routes in order to find a match. While this approach does not scale well to large numbers of routes, it is simple and easy for the average ruby programmer to understand.
Rails approach to routing is far more complex than pretty much all other Ruby web frameworks. It requires knowledge of deterministic finite automata. Computer science majors may remember how to do this if they took compiler courses at university, but the average Ruby programmer would probably need to do substantial research to even begin to understand how it works.
Roda’s approach of using a routing tree is similar in complexity to an array of routes. You start off at the top of the routing tree block. Each method call checks to see if the current route matches the request. If so, the process is repeated for the block you pass to the method, otherwise you continue to the next method.|So a routing tree’s processing is equivalent to iterating over a small array of routes for each branch in the tree, instead of iterating over one large array of routes.
How does the internal complexity of the routing implementation impact users of the framework? Well, the higher the implementation complexity, the more difficult it is to find other programmers who can understand the code, add features to it, and fix bugs in it. In general, more complex code is harder to debug than simpler code. As a general rule, unless there is a substantial benefit from complexity, simplicity should be preferred.
So in terms of simplicity, Roda’s approach to routing is about as simple as Sinatra’s approach in terms of internal complexity, and far simpler than the approach Rails uses for routing. However, in most cases, the internal complexity of a framework does not matter that much to users of the framework.|What really matters to users of a framework is whether the framework allows the user to write simple code. If a user can write simpler code to implement their web application, they are likely to decrease the number of bugs in their web application, and make it easier to fix those bugs and add additional features.
The simplicity advantage that Roda offers over other Ruby web framworks is due to its integration of routing with request handling. Roda recognizes that routing a request is not an end in itself, it is purely a means to make sure the request is handled correctly.|With a routing tree, routing is not separate from request handling, the two are integrated. So as you are routing a request, you can also be handling the request. In other Ruby web frameworks, routing is separate from request handling.
The advantages of the integration of routing and request handling may not be obvious. I gave a brief example earlier, but I am going to discuss the integration in more detail now, and then discuss what web frameworks that lack this integration offer in terms of similar functionality.
Let me first start with some example Sinatra code. This is fairly simple, we have two routes, both related to a specific album, one for GET and one for POST. When I was using Sinatra, this was pretty typical in many of my applications.
get '/albums/:id' do
@album = Album[params[:id].to_i]
erb(:album)
end
post '/albums/:id' do
@album = Album[params[:id].to_i]
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
The main issue with this approach is that it leads to duplication. Here you see the path is duplicated in both of the routes.
get '/albums/:id' do
@album = Album[params[:id].to_i]
erb(:album)
end
post '/albums/:id' do
@album = Album[params[:id].to_i]
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
The conversion of the parameter from a string to an integer, and the retrieval of the album from the database, is also duplicated in both of the routes.
get '/albums/:id' do
@album = Album[params[:id].to_i]
erb(:album)
end
post '/albums/:id' do
@album = Album[params[:id].to_i]
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
Using a routing tree, you can simplify things.
r.is 'albums', Integer do |id|
@album = Album[id]
r.get do
view(:album)
end
r.post do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
end
Instead of duplicating the path in both cases, it is specified once in the branch. Additionally, by using the Integer class as the matcher, we can handle the conversion of the parameter to integer in both of the routes. Another advantage of using Integer as the matcher is that this route will only match if the id is provided as an integer, it will not match in other cases.
r.is 'albums', Integer do |id|
@album = Album[id]
r.get do
view(:album)
end
r.post do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
end
As soon as the branch is taken, the album is retreived from the database.
r.is 'albums', Integer do |id|
@album = Album[id]
r.get do
view(:album)
end
r.post do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
end
In both the get and post routes, the album instance variable is available for use.
r.is 'albums', Integer do |id|
@album = Album[id]
r.get do
view(:album)
end
r.post do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
end
So one of the primary advantages of a routing tree is that it allows you to easily eliminate redundant code, by moving it to the highest branch where it is shared by all routes under that branch.
r.is 'albums', Integer do |id|
@album = Album[id]
r.get do
view(:album)
end
r.post do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
end
Now, it is possible to do something similar in Sinatra. You can use before blocks in Sinatra and provide a path to the before block, and Sinatra will iterate over all of the before blocks before routing the request, checking each to see if the request path prefix matches the before block. If so, it will yield to the before block. So using a before block, you can still convert the parameter to integer and retrieve the album from the database in a single place.
before '/albums/:id' do
@album = Album[params[:id].to_i]
end
get '/albums/:id' do
erb(:album)
end
post '/albums/:id' do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
However, now note that you need to specify the path itself three times, instead of just once.
before '/albums/:id' do
@album = Album[params[:id].to_i]
end
get '/albums/:id' do
erb(:album)
end
post '/albums/:id' do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
Unlike the routing tree example, the shared behavior is in a separate lexical scope, which I think makes it more difficult to understand the connection between the shared behavior and the two routes. The two routes are also in separate lexical scopes, which makes it more difficult to understand how they are connected.|Additionally, using before blocks like this in Sinatra has a negative effect on performance. Before blocks are processed pretty much the same way as route blocks, so adding a before block is equivalent to adding a route, and since routing performance degrades linearly as the number of routes increases, adding before blocks like this hurts preformance for the entire application.
before '/albums/:id' do
@album = Album[params[:id].to_i]
end
get '/albums/:id' do
erb(:album)
end
post '/albums/:id' do
@album.update(params[:album])
redirect "/albums/#{@album.id}"
end
In Rails, you specify the routes in the config/routes.rb file, and the code to handle the routes goes in a controller class in a separate controller file, using a separate method per route.|This separation of routing code and controller code is one of the things I dislike about Rails, as it adds significant conceptual overhead, since it takes more work to figure out where the code that handles a route will be located.
def show
@album = Album.find(params[:id])
render(action: 'edit')
end
def update
@album = Album.find(params[:id])
@album.update_attributes(params[:product])
redirect_to @album
end
As in the initial Sinatra example, this approach duplicates the parameter conversion and retrieval of the album from the database in both methods.
def show
@album = Album.find(params[:id].to_i)
render(action: 'edit')
end
def update
@album = Album.find(params[:id].to_i)
@album.update_attributes(params[:product])
redirect_to @album
end
Rails also offers a way to eliminate the redundant code, using a before filter to specify a method to call before the action, for a given set of actions.
before_filter :find_album, only: [:show, :update]
def show
render(action: 'edit')
end
def update
@album.update_attributes(params[:product])
redirect_to @album
end
private
def find_album
@album = Album.find(params[:id].to_i)
end
The main issue with this approach is that if you add more routes where you want to retrieve the album, you need to remember to update the only option to the before filter.|Also, just like when you try to share behavior in Sinatra, the shared behavior is in a separate lexical scope, which makes it more difficult to understand how it is connected to the route handling methods.
before_filter :find_album, only: [:show, :update]
def show
render(action: 'edit')
end
def update
@album.update_attributes(params[:product])
redirect_to @album
end
private
def find_album
@album = Album.find(params[:id].to_i)
end
So Sinatra and Rails and most other web frameworks can use before filters to emulate code placed at the top of a routing tree block. However, how can you handle more complex cases? Assume you want to run code only for some of the routes in a branch, but not run code for other routes in a branch. As Roda’s routing tree is executed in the context of a request, you can run arbitrary code at any point during routing, not just at the top of the blocks.
route do |r|
r.post 'login' do
session[:logged_in] = true
end
require_login!
r.on 'albums' do
# ...
end
end
One of the common places where this is useful is when doing access control. For example, if part of your site allows anonymous access, and part of your site does not, you can place the part that allows anonymous access first, and then run the check for a login, and then have the rest of the routes where anonymous access is not allowed.
route do |r|
r.post 'login' do
session[:logged_in] = true
end
require_login!
r.on 'albums' do
# ...
end
end
Note that this is an issue with most sites that support authentication, since the login action must be available to users who are not already authenticated.
route do |r|
r.post 'login' do
session[:logged_in] = true
end
require_login!
r.on 'albums' do
# ...
end
end
This type of access control is kind of a pain to handle in Sinatra. When I was using Sinatra, the usual way I would handle this would be to specifically whitelist each path or prefix that allowed anonymous access. This works OK if you only have a small number of paths that allow anonymous access, but quickly becomes difficult if you have a large number of separate paths that allow anonymous access.|I suppose another approach is to put the require_login method in every single Sinatra route that requires a login, but that’s an even larger pain.
before do
unless env['PATH_INFO'] =~ \
%r{\A/login|/foo|/bar/baz}
require_login!
end
end
Implementing this type of access control is also more complex in Rails. Usually in Rails, this would be handled by using a before filter in ApplicationController that required a login.
ApplicationController.before_filter :require_login!
Then, in each controller where you want to allow anonymous access, you need to skip the before filter. This spreads the access control handling to multiple places in the application, and again requires you to specifically whitelist all of the allowed actions.
ApplicationController.before_filter :require_login!
LoginController.skip_before_filter :require_login!
FooController.skip_before_filter :require_login!, \
except: [:index]
BarController.skip_before_filter :require_login!, \
except: [:baz]
In Roda, since the routing tree is directly executed, you can include arbitrary logic that affects routing at any point during routing. In this example, you have a routing tree that makes the list of albums available to everyone.
r.on 'albums' do
r.get 'list' do
view(:album_list)
end
if admin?
r.run AdminSite
end
end
For admins, it also routes other requests to an AdminSite rack application.
r.on 'albums' do
r.get 'list' do
view(:album_list)
end
if admin?
r.run AdminSite
end
end
In Sinatra, this is more difficult. You have to add routes for each request you want to support, with splats so that Sinatra will only do a prefix match on the request path.
get '/albums/list' do
erb(:album_list)
end
block = proc do
pass if admin?
e = env.dup
e['PATH_INFO']=e['PATH_INFO'].sub('/albums', '')
e['SCRIPT_NAME']=e['SCRIPT_NAME'] + '/albums'
AdminSite.call(e)
end
get '/albums/*', &block
post '/albums/*', &block
You then have the block pass if it is not an admin request.
get '/albums/list' do
erb(:album_list)
end
block = proc do
pass if admin?
e = env.dup
e['PATH_INFO']=e['PATH_INFO'].sub('/albums', '')
e['SCRIPT_NAME']=e['SCRIPT_NAME'] + '/albums'
AdminSite.call(e)
end
get '/albums/*', &block
post '/albums/*', &block
If it is an admin request, you need to create a new environment to call the AdminSite rack app with. Then you need to call the AdminSite rack app.|I am sure this is possible in Rails too, but I do not actually know how to do it. You can use mount in your routes file to mount a rack app at a given prefix, but I am not sure if that also supports the ability to check for things like administrative permissions before dispatching to the rack app.
get '/albums/list' do
erb(:album_list)
end
block = proc do
pass if admin?
e = env.dup
e['PATH_INFO']=e['PATH_INFO'].sub('/albums', '')
e['SCRIPT_NAME']=e['SCRIPT_NAME'] + '/albums'
AdminSite.call(e)
end
get '/albums/*', &block
post '/albums/*', &block
These improvements may seem small, but taken together, they can result in much simpler applications. While it is possible to eliminate the redundant code without a routing tree using before filters, in most Sinatra applications I have looked at, that is not done as it is not natural. The usual case is code is just copied into all routes that need it.|This does not surprise me, because when I was writing Sinatra applications, from about 2008 to 2014, that’s what I would do. Using a separate before filter for every set of GET and POST routes, while possible in Sinatra, feels unnatural.
Back in 2015, a year after I created Roda, I analyzed one of the applications that I had worked for on a couple years, which is a process automation system my office uses. This application was originally built using Sinatra, and it was switched to Roda in 2014.|When it was using Sinatra, it had redundant code in most of the routes. When I switched it to a using a routing tree, I was able to eliminate the redundant code by moving it up to the highest enclosing branch where it was shared by all the routes.
Back in 2015, the application had 79 total routes.
To get to those 79 routes, there were a total of 36 branches in the routing tree where the branch contains other branches or routes.
Of those 36 branches containing other branches or routes, 25 contained code that was shared by all routes under the branch. In most cases, the code that was shared was either retrieving objects from the database or enforcing access control.
That means 70% of the time there were branches in the routing tree, the integration of routing and request handling resulted in the elimination of redundant code.|It also means that if I wanted to eliminate the same redundant code in Sinatra or Rails, I would have to add 25 separate before filters.
For this presentation, I decided to reanalyze the application to determine if the situation had changed.
Currently, the application had 72 total routes. This application has gained some features and lost others. I think the main reason for the decrease in the number of routes was that the application used to have its own routes to handle authentication, and now it uses Rodauth for authentication, so those routes are no longer counted. Rodauth is an authentication framework built on top of Roda, and all Rodauth routes use Roda’s routing tree to share logic. However, to be conservative, I didn’t consider the Rodauth routes in this analysis.
To get to those 72 routes, there are a total of 35 branches in the routing tree where the branch contains other branches or routes. This is a slight decrease in the number of branches.
Of the 35 branches containing other branches or routes, 29 contained code that was shared by all routes under the branch, which was a significant increase compared to the 25 branches that had shared code back in 2015. In the last seven years, we’ve designed newer parts of the application to take advantage of Roda’s ability to more easily share code.
That means that with the current codebase, 83% of the time there are branches in the routing tree, Roda’s integration of routing and request handling resulted in the elimination of redundant code.|It means that if I wanted to eliminate the same redundant code in Sinatra or Rails, I would have to add 29 separate before filters.|This analysis also shows that if you actively build your applications around the use of a routing tree, you can derive even greater benefits from sharing code between multiple routes.
Using a routing tree makes it natural to share code for all routes under a branch, so web applications that use a routing tree naturally tend to avoid redundant code. Using before filters to eliminate redundant code is not natural in most other web frameworks, so even though it is possible, it often is not done, and the natural approach leads to redundant code.
One big problem I have seen related to redundant code in other web frameworks is that the redundant code is not always consistent. It is common to have two similar routes where you want to have the same behavior. However, over time, you make a change in only one route instead of in both routes.
It is especially bad when the inconsistency is related to access control, because when that happens, often it results in a security vulnerability in the application. I have seen this not just in other people’s applications, but in applications I converted from Sinatra and Rails to Roda. Avoiding redundancy and inconsistency does not eliminate security issues, but it does help to reduce them.
Note that in order to extract maximum benefit from a routing tree, you need to structure your paths in such a way that shared behavior can be determined before the entire path has been routed. These days, this type of path structure is pretty natural.
For example, if you structure paths like this, they are naturally routing tree friendly.
/albums/1
/albums/1/tracks
/albums/1/similar
That’s because as soon as the routing tree has routed the /albums/1 prefix, it can retrieve the album from the database, so all the routes under the /albums/1 branch can share it.
/albums/1
/albums/1/tracks
/albums/1/similar
However, if you use Rails 1 style /controller/action/id routes, you cannot derive as much benefit from a routing tree.
/albums/show/1
/albums/tracks/1
/albums/similar/1
This is because the segment containing the albums’s id appears at the end of the path, after the branching for the show/tracks/similar segments has already taken place.|I have multiple applications that were initially developed using pre-Rails 1.0, and were updated all the way to Rails 4.1 without changing the path structure, and when I switched them to using a routing tree, I still ended up with redundant code in many routes.
/albums/show/1
/albums/tracks/1
/albums/similar/1
You should keep these path structure considerations in mind if you are planning to convert an existing web application to use a routing tree.|If you are creating a new application, or are willing to change the path structure of an existing application, you can design the paths to be friendly to a routing tree approach.
Hopefully that section gave you an understanding of how Roda’s use of a routing tree can allow you to write simpler code.
I am now going to talk about reliability. There are a few different ways to look at reliability.
One way to look at reliability is in terms of the framework itself being reliable. You could call this internal reliability. Part of Roda’s reliability come from being fairly simple internally. Another part comes from the fact that it has 100% branch and line coverage of all code. However, like internal simplicity, internal reliability is a feature that most users do not focus on.
Most users care more that the framework allows them to write reliable applications. Roda has two features that result in your applications being more reliable.
One way that Roda can make your applications more reliable is allowing them to be frozen at runtime. By freezing your Roda application after it is configured but before accepting requests, you can eliminate issues caused by the application being modified at runtime. This can detect many different types of thread-safety issues, raising an obvious error if they occur at runtime.|Roda pioneered the approach of freezing web applications at runtime years ago, and as far as I know, it is still the only Ruby web framework to support and encourage being frozen at runtime.
Another way Roda increases reliability is to avoid polluting your application with unnecessary variables, methods, and constants. Roda believes you should be able to use the variables, methods, and constants you want in your application. For example, one of my production applications deals with many different types of requests, such as requests for time off, requests to take training classes, requests for access to projects, etc.. Another application deals with responses received from other companies.
It is natural in my application to store a time off request in an instance variable named request, and a company response in an instance variable named response, since these will be the instance variables used in the related templates.
r.get '/time_off', Integer do |request_id|
@request = TimeOffRequest[request_id]
view(:time_off)
end
r.get '/response', Integer do |response_id|
@response = CompanyResponse[response_id]
view(:response)
end
You can see here where these instance variables are set. And this approach works just fine in Roda.
r.get '/time_off', Integer do |request_id|
@request = TimeOffRequest[request_id]
view(:time_off)
end
r.get '/response', Integer do |response_id|
@response = CompanyResponse[response_id]
view(:response)
end
Unfortunately, if you are using Sinatra, this approach does not work. Here’s the equivalent Sinatra code.
get '/time_off/:request_id' do
@request = TimeOffRequest[params[:request_id].to_i]
erb(:time_off)
end
get '/response/:response_id' do
@response = CompanyResponse[params[:response_id].to_i]
erb(:response)
end
This does not work in Sinatra because Sinatra uses the request instance variable internally to store information related to the HTTP request. So if you do this, Sinatra will raise an exception later.
get '/time_off/:request_id' do
@request = TimeOffRequest[params[:request_id].to_i]
erb(:time_off)
end
get '/response/:response_id' do
@response = CompanyResponse[params[:response_id].to_i]
erb(:response)
end
Similarly, Sinatra stores the HTTP response in the response instance variable. So if you set the response instance variable, Sinatra will raise an exception later.
get '/time_off/:request_id' do
@request = TimeOffRequest[params[:request_id].to_i]
erb(:time_off)
end
get '/response/:response_id' do
@response = CompanyResponse[params[:response_id].to_i]
erb(:response)
end
Roda avoids the problems Sinatra has by prefixing all instance variables used internally with an underscore. Rails uses a similar approach.
r.get '/time_off', Integer do |request_id|
@request = TimeOffRequest[request_id]
view(:time_off)
end
r.get '/response', Integer do |response_id|
@response = CompanyResponse[response_id]
view(:response)
end
Unfortunately, when it comes to method pollution, Rails does not fair nearly as well.
As of Rails 7, inside a Rails controller action, there are over 300 additional methods not prefixed by an underscore, beyond the methods defined by default by Ruby in Object. If you override any of these methods, you can potentially cause problems with the framework and break things.
Inside the Roda routing tree, there are only 6 additional methods defined by default. This reduces the chance that you’ll want to define a method that the framework uses.
So those are the three approaches Roda uses to achieve high reliability. First, keep the internals simple and have 100% line and branch coverage. Second, run frozen in production to avoid possible thread-safety issues. Third, avoid polluting the execution environment by avoiding internal instance variables that will conflict with instance variables the user has set, and limit the methods defined as much as possible.
Now that I have discussed about how Roda achieves its goals of performance, simplicity, and reliability, we can discuss the fourth goal, which is extensibility. Roda’s goal of extensibility means that Roda has a very small core, which is focused on routing requests via the request path and method.
All non-core features are added via plugins. Roda ships with over 100 plugins, and there are many plugins that are shipped in external gems. Plugins can add methods to the scope of the route block, as well as methods to the request and response classes.
The idea behind Roda is that each plugin is like a tool, and Roda basically comes with a complete toolkit. Like a physical toolkit, you won’t be using every tool in every job. For example, some jobs require some tools, like a screwdriver, and other jobs require other tools, like a hammer.|Similarly, when you are building a web application, some applications may require HTML template rendering, and other applications may require the ability to return data in JSON format.|With Roda, you choose the appropriate tools from Roda’s toolkit, and build your site using those plugins. You do not have to pay the memory or processor cost for any tools that you are not using. One of Roda’s core tenets is that you only pay for what you use.
To give you a flavor for Roda, I will now go over some of the plugins that ship with Roda, and the features they add.
If you are building a website that returns HTML, you are probably going to want to use the render plugin. The render plugin builds on top of the Tilt library, which is the same library that Sinatra uses for template rendering. Tilt supports a wide variety of different template libraries, so pretty much any template type you would like to use is probably supported. Like Rails, Roda’s default template engine is ERB.|The render plugin has extensive support for compiled templates, ensuring that template rendering is as fast as possible. It even uses compiled template support in development mode to improve development velocity.
If you want to handle automatic generation of javascript and/or CSS during development, and compile javascript and/or CSS into a single files for use in production, Roda ships with an assets plugin for that. Roda’s assets plugin is configured via a simple options hash, and does not require any alternative language runtimes such as node installed, unless such a runtime is required by the asset template engine in use.
If you want to serve static files from a directory, Roda has a public plugin that supports that. Because Roda exposes the public file serving using a routing tree, it is possible that have public files served only if the request has passed access control checks.
In some cases, you may have multiple directories used to serve static files, such as to support different file types or to serve to different classes of users. Roda has a multi_public plugin that supports that, so you can serve separate public directories at any point in the routing tree.
As an example of how minimal Roda is, core Roda does not come with HTML escaping, because not all applications need it. The h plugin adds an h method for handling HTML escaping of strings. In some cases, even for applications generating HTML, the h plugin is not needed, because the render plugin can support automatic HTML escaping.
For API applications, that are designed to return JSON instead of HTML, Roda ships with a json plugin. The json plugin allows your routing blocks to return hashes, arrays, or other configured objects, and will automatically convert those objects to JSON to use as the response. This makes it so you don’t have to convert the objects to JSON manually.
By default, Roda only handles the same request types that are handled by Rack, related to HTML form submissions. If your application needs to accept JSON input, Roda comes with a JSON parser plugin, which will parse request bodies submitted in JSON format.
One of the plugins I use in most of my applications is called symbol views, which allows your route blocks to return a symbol, and treats the symbol as the name of a template name to render. This reduces a lot of duplication that occurs in applications with a large number of templates.
Another example of Roda’s default minimalism is that it only has methods for handling GET and POST requests by default. If you want to add methods to handle requests for other HTTP verbs, such as PUT or DELETE, you can use the Roda’s all_verbs plugin.
One of the limitations of Roda’s default routing tree is that all routing must happen in a single Ruby block. Since you cannot have a Ruby block that spans multiple files, this means that all routing must happen in a single Ruby file, which is only appropriate for small web applications.|Roda has multiple ways of splitting the routing tree into multiple Ruby blocks, in order to support larger applications. The most common plugin to use to support multiple routing blocks is hash_routes, which allows using a separate block for each top-level branch of the routing tree. For very large web applications, it can be used in a nested format to support sub-branches of the routing tree. I use this in all of my large web applications to separate routing each top-level branch of the routing tree into its own block and file.
Roda ships with a content_security_policy plugin, to enable you to easily configure an appropriate security policy for your application, which can be customized on a per-branch or per-route basis.
One of the largest security issues in Ruby web applications comes from incorrectly handling submitted parameters. Due to the fact that Ruby uses dynamic typing, it is easy for attackers to submit unexpected types in parameters.|Roda ships with a typecast_params plugin that handles almost all parameter typecasting needs, allowing you to convert the type of submitted parameters to the expected type before the parameters are used.
If you want to send email in your web application, Roda has a mailer plugin for that. The mailer plugin uses the routing tree to route requests to send email, allowing similar emails to share logic, just as web requests in the same branch can share code. This generally has the same benefits that a routing tree offers for web requests, resulting in simpler email generation code.
If you want to process received email, Roda has a mail_processor plugin that supports that. This is commonly used by applications to process replies to emails that are sent by the application, so that users can interact with your application by replying to email. It uses a modified routing tree approach to share logic during the processing of received emails, which generally results in simpler processing code.
Roda ships with a route_csrf plugin that implements strong cross site request forgery protection, so that all forms need to be submitted with a token not just valid for the current session, but that also matches the expected request method and path.|This protection offered by the route_csrf plugin is significantly stronger that the CSRF protection Rails uses by default, since Rails will still accept generic CSRF tokens even if you configure it to generate route-specific CSRF tokens. This CSRF protection can be implemented at arbitrary points during routing, making it easy to check CSRF tokens for some requests and not others.
Finally, Roda includes a session plugin for encrypted session support. This uses a secure approach that checks for a valid HMAC before attempting to decrypt a submitted session cookie, avoiding timing and other cryptographic attacks on sessions.
To sum up, Roda has a small core, where almost all features are supported via plugins, and allows you to choose which plugins you use for your application, so that you do not have to pay for the parts of Roda that you are not using. This is in strong contrast to Rails, which ships with all features enabled by default, where you have to choose which high-level features you want to disable. This is also in contrast to Sinatra, which does not include support for many features that are shipped with Roda.
Many people have the idea that if you use something that is not Rails, you end up having to rebuild most of what Rails gives you. That may be true with Sinatra, but definitely is not true with Roda. In some cases, Roda ships with an equivalent to features that Rails offers. In other cases, there are third-party libraries that work with both Rails and Roda that are superior to the features that Rails offers you by default. I will briefly go over the different parts of Rails, and what the equivalent could be for Roda.
ActionPack is really the heart of Rails, implementing the routing and handling of requests.
Core Roda and the many of the routing plugins that ship with Roda are a direct replacement for ActionPack.
ActionView is what Rails uses for template rendering.
As I mentioned, Roda’s render plugin offers equivalent functionality.
ActionMailer is what Rails uses to send email.
Roda’s mailer plugin handles the same need.
ActionMailbox is what Rails uses to process received email.
Roda’s mailbox_processor plugin handles that use case.
So those four parts of Rails have direct equivalents in Roda. Now let’s look at some other parts of Rails that do not have direct equivalents in Roda, but can be handled by superior third party libraries that work in both Rails and Roda.
Rails uses ActiveRecord by default for database access.
In general with Roda, you would probably want to use the Sequel database library for database access, as it is usually significantly faster and has more features than ActiveRecord. Sequel also uses a similar plugin system design so you do not have to pay for the parts you are not using.
Rails uses ActiveModel as an abstraction layer for model objects, handling things like validations.
Sequel supports many of the same features as ActiveModel, and can comply with the ActiveModel API using the Sequel active_model plugin.
ActionCable is what Rails uses to implement Websockets support.
In general, you can replace ActionCable with AnyCable, which offers much better performance and is not tied to Rails.
Rails uses ActiveStorage to handle and process uploaded files.
Shrine is a superior third party library for handling uploaded files, and it supports both Rails and Roda.
Rails uses ActiveJob as an abstraction layer for various job libraries.
Unless you really need such an abstraction layer, you can remove it completely and use the native API for the job library you are using, such as Sidekiq.
Rails uses ActionText to handle rich text content editing, which uses the Trix Javascript library to implement the editor.
You can replace ActionText with something like CKEditor on the Javascript side, and storing data using Sequel instead of ActiveRecord.
The final piece of Rails is ActiveSupport, which modifies many of Ruby’s core classes, and often ends up breaking things in libraries not designed around usage with Rails.
In general, you can replace ActiveSupport with Ruby’s core classes and standard library. In my opinion, one of the best things about using any web framework than Rails is that you are not forced into using ActiveSupport.
So if you are familiar with Rails,
Hopefully you can see how you can still handle all of the same needs while using Roda.
Choosing to use Roda instead of Rails involves a tradeoff. First, while I think Roda’s approach to routing is in general technically superior to Rails, there is one feature that Rails offers that Roda does not offer.
That is route introspection, or the equivalent of showing what routes are available in the application. Because routes are not stored in a data structure when using a routing tree, since a routing tree is really just Ruby code, you cannot introspect your routes like you can in most other ruby web frameworks.|In my applications, this does not matter, but there are some applications that rely on introspection of the routes, and those would need to be handled differently when using Roda.
There is an external route_list plugin that you can add to Roda that gives you the equivalent of route introspection, but it requires special comments on all routes, which means extra work on the user’s part to setup the comments correctly.
Not being able to introspect the routes is probably the main technical disadvantage of Roda. I do not think it is a big issue, but it is something you should be aware of before considering a switch.
One other major consideration when deciding whether to use Roda is related to network effects. I mentioned that Roda is the fourth most popular Ruby web framework, but it is still much less popular than Rails or Sinatra.|It is definitely going to be easier to find Ruby programmers who already know Rails than it will be to find Ruby programmers who already know Roda. On the flip side, it is probably significantly easier to learn Roda than Rails, as Roda is smaller and simpler.|Similarly, it is going to be easier to find Ruby libraries that already work with Rails than it will be to find Ruby libraries that already work with Roda. While Roda has good options for most common web programming needs, Rails is going to offer considerably more options. For less common web programming needs, you are more likely to find a library that already works with Rails, and it is possible you may not be able to find a library that already works with Roda.
So the choice of whether to use Roda instead of Rails depends mostly on how much you value the technical advantages that Roda brings, compared to the network effect advantages of Rails.|I hope you had fun learning about Roda. Let me briefly go over what I discussed today.
I discussed how Roda’s routing tree allows you to create simpler web applications, by allowing you to easily share logic between related routes.
I discussed how Roda names internal instance variables so they do not conflict with instance variables you use in your application, and it limits the methods defined to the bare minimum needed to function. I also discussed how Roda is designed to run with the application frozen, to easily detect undesired modifications at runtime.
I discussed how Roda is built with a very small core, and ships with over 100 plugins. This allows Roda to operate like a toolbox, where you only have to pay for the tools that you use.
Finally, I discussed and gave some examples showing that Roda is much faster than other Ruby web frameworks.
If you are interested in learning more about Roda, please visit the website at roda.jeremyevans.net, which has extensive reference documentation on Roda itself, as well as all plugins that ship with Roda.
In addition to the documentation on Roda’s website, there is also a free online book about Roda named Mastering Roda. This book was originally written by Federico Iachetti, and a few years ago it was open sourced. I have edited or rewritten large parts of the book, and now keep it up to date with changes in Roda. So if you are looking to learn Roda from scratch, it is a great place to start.

If you enjoyed this presentation, and want to read more of my thoughts on Ruby programming, consider picking up a copy of Polished Ruby Programming.
That concludes my presentation. I want to thank you all for listening to me talk about Roda.
If you have any questions, I am happy to answer them now.