
| z, ? | toggle help (this) |
| space, → | next slide |
| shift-space, ← | previous slide |
| d | toggle debug mode |
| ## <ret> | go to slide # |
| r | reload slides |
| n | toggle notes |
Minyasan, konbanwa. RubyKaigi no saigo no kicho koen e yokoso. Sumimasen, watashi no nihongo chishiki wa kagira rete ori, eigo de tsudzukenakereba. (Good evening everyone. Welcome to the closing keynote of RubyKaigi. Apologies, my knowledge of Japanese is limited, and I must continue in English.)

Today, I will be discussing some optimization techniques used in Sequel and Roda, providing some background on why these libraries are significantly faster than their alternatives, as shown in TechEmpower’s independent benchmarks.
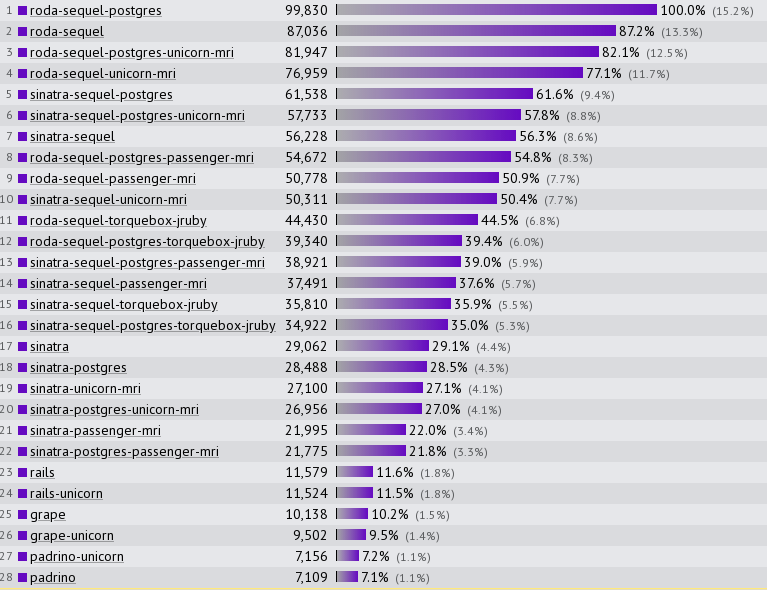
TechEmpower has been benchmarking web frameworks in many languages since 2013. They have been benchmarking Rails and Sinatra since the beginning. In 2017, they started benchmarking Sequel with Roda, and since then, the combination of Sequel and Roda has been leading TechEmpower’s benchmarks of Ruby web frameworks.

Sequel is a toolkit for database access in Ruby, and Roda is a toolkit for writing web applications in Ruby. While I am not the original author of either library, I have been maintaining both libraries for many years, and have added all of the optimizations I will be discussing today.

![]()
My name is Jeremy Evans. I started writing Ruby libraries in 2005, and started contributing to Ruby development in 2009.|My day job has me responsible for managing all information technology operations for a small government department. Part of that job is maintaining applications of all sizes written in Ruby using Sequel and Roda.

While I added the optimizations I am discussing today to Sequel and Roda, many of the optimizations I learned about from others. My experience is that it is easier to implement optimization approaches that other developers have created, compared to developing your own optimization approaches.
With that in mind, the goal of this presentation is to demonstrate some optimization techniques, approaches, and principles that you can use to improve the performance of your own Ruby code, hopefully saving you time should you want to optimize your own libraries or applications.
The first optimization principle, is the fastest code is usually the code that does the least. If you want fast code, as much as possible, avoid unnecessary processing during performance sensitive code paths.
An old Ruby web framework named Merb had a great motto related to this, No code is faster than no code. In other words, if you can get the same result without executing any code, any approach that requires executing code will be slower.|A major reason Sequel and Roda are faster than their alternatives is that they try to execute less code, at least by default.
No Code is Faster than
No Code—Merb Motto
Here is the class method that Sequel uses to create new model objects.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
The method name used is call, which is kind of an odd choice for a method that creates objects. I will discuss a little bit later why call is used as the method name, as that relates to a different optimization, but notice how this method does very little.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
It takes the values hash that was retreived from the database.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
It allocates a new model instance.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
It sets the values hash to an instance variable.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
Then it returns the instance.
def call(values)
o = allocate
o.instance_variable_set(:@values, values)
o
end
Here is a comparison with a similar instance method that ActiveRecord uses to create instances using hashes retreived from the database.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
yield self if block_given?
_run_find_callbacks
_run_initialize_callbacks
self
end
And here are some comments showing what each of the called methods do.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
When you compare these side to side, it should not be a surprise that Sequel is faster. Sequel does much less in this performance sensitive code path. So how is Sequel able to avoid executing most of this code? Let’s go over the different sections in this method.
# ActiveRecord # Sequel
def init_with_attributes(attributes, new_record = false) def call(values)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes instance_variable_set(:@values, values)
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end end
Let’s start with this code. ActiveRecord starts by initializing all of these instance variables, mostly to nil or false.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
@readonly = false
@destroyed = false
@marked_for_destruction = false
@destroyed_by_association = nil
@new_record = true
@_start_transaction_state = {}
@transaction_state = nil
@new_record = new_record
It does set new_record to true here.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
@readonly = false
@destroyed = false
@marked_for_destruction = false
@destroyed_by_association = nil
@new_record = true
@_start_transaction_state = {}
@transaction_state = nil
@new_record = new_record
But ends up setting new_record back to false here, because the method is usually called with only one argument, and the new_record local variable is the second argument, which defaults to false.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
@readonly = false
@destroyed = false
@marked_for_destruction = false
@destroyed_by_association = nil
@new_record = true
@_start_transaction_state = {}
@transaction_state = nil
@new_record = new_record
Probably the most controversial optimization technique that both Sequel and Roda use is that they both avoid initializing instance variables to nil or false.
Assuming you have 6 instance variables, not initializing the instance variables to nil or false is about 150% faster. For both Sequel and Roda, this optimization improves performance by a few percentage points in real world benchmarks.
The reason this optimization is controversial is that accessing an uninitialized instance variable generates a warning in verbose mode. This verbose mode warning slows down all instance variable access, even if all instance variables are initialized.
I submitted a patch to speed up instance variable access by about 10% by removing this warning if verbose mode was not enabled at compile time,
but unfortunately that was not considered enough of an improvement to justify the backwards compatibility breakage.
Getting back to our example, there is one instance variable that is set to a value that is not nil or false, and it is start_transaction_state. As you might expect, this instance variable is only used for transactions, so if you are just retrieving a model instance and not saving it, it is not necessary to set this during initialization. Setting it allocates an unnecessary hash, which hurts performance.|In similar cases, Sequel will usually delay allocating the instance variable until it is actually needed.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
@readonly = false
@destroyed = false
@marked_for_destruction = false
@destroyed_by_association = nil
@new_record = true
@_start_transaction_state = {}
@transaction_state = nil
@new_record = new_record
This is another general optimization principle. Unless there is a high probability you will need to execute something, it is best to delay execution until you are sure you will need it, otherwise you may be doing unnecessary work.
After setting the instance variables, the ActiveRecord model instance then asks its class to define instance methods for all of the model’s attributes. This needs to be called for the first instance retrieved, because ActiveRecord does not define the attribute methods until then.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
self.class.define_attribute_methods
return false if @attribute_methods_generated
After the first instance has been retrieved, this method just returns without doing anything, so asking the class to define the attribute methods is slowing down all model instance creation after the first record. Sequel avoids this performance issue.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
self.class.define_attribute_methods
return false if @attribute_methods_generated
Instead of waiting until a model instance is retreived to define the attribute methods, Sequel::Model defines the attribute methods when you create the class. That way all model instances can assume the attribute methods have already been created, and they don’t need to ask the model class to create them, speeding up all model instance creation.
class MyModel < Sequel::Model
# attribute methods already defined
end
This represents another general optimization principle. Any time you have code is called many times, see if there is a way that you can run that code once instead of many times. Once is better than many.
In Big-O terms, O(1) is better than O(n).
Applied to web applications, this principle means that if you should prefer to run code during application initialization, before accepting requests, if it will allow you to save time while processing requests. When the application process starts, initialization only happens once, but the process may be handling millions of requests during its runtime.
The last thing that ActiveRecord does during model instance creation is run the find and initialize hooks for the model instance. However, if the model does not have any find or initialize hooks, this slows down model instance creation. It would be best to only run this code for the models where you actually need to use find or initialize hooks.
# ActiveRecord
def init_with_attributes(attributes, new_record = false)
init_internals
#@readonly = false
#@destroyed = false
#@marked_for_destruction = false
#@destroyed_by_association = nil
#@new_record = true
#@_start_transaction_state = {}
#@transaction_state = nil
@new_record = new_record
@attributes = attributes
self.class.define_attribute_methods
# return false if @attribute_methods_generated
yield self if block_given?
_run_find_callbacks
#callbacks = __callbacks[:find]
#unless callbacks.empty?
# # ...
#end
_run_initialize_callbacks
#callbacks = __callbacks[:initialize]
#unless callbacks.empty?
# # ...
#end
self
end
_run_find_callbacks
callbacks = __callbacks[:find]
unless callbacks.empty?
# ...
end
_run_initialize_callbacks
callbacks = __callbacks[:initialize]
unless callbacks.empty?
# ...
end
Sequel avoids the need for all models to check for initialize hooks, by moving the initialize hook into a plugin.
class MyModel < Sequel::Model
plugin :after_initialize
end
Sequel and Roda share the idea of doing the minimum work possible by default. However, they are still designed to solve the same problems you can solve with other frameworks. In order to be as fast as possible by default, but still be flexible enough to solve the same problems, both Sequel and Roda use similar plugin systems.
Both Sequel’s and Roda’s plugin systems are designed around the same basic idea. Each has an empty base class with no class or instance methods.
class Sequel::Model
end
The class is extended with a module for the default class methods,
class Sequel::Model
extend Sequel::Model::ClassMethods
end
and a module for the default instance methods is included in the class.
class Sequel::Model
extend Sequel::Model::ClassMethods
include Sequel::Model::InstanceMethods
end
You use the plugin class method to load plugins. Each Sequel or Roda plugin can contain a class methods module and/or an instance methods module.
class MyModel < Sequel::Model
plugin :after_initialize
end
Loading the plugin extends the class with the plugin’s class methods module.
class MyModel < Sequel::Model
plugin :after_initialize
# extend AfterInitialize::ClassMethods
end
It also includes the plugin’s instance methods module in the class.
class MyModel < Sequel::Model
plugin :after_initialize
# extend AfterInitialize::ClassMethods
# include AfterInitialize::InstanceMethods
end
This is how part of Sequel’s after_initialize plugin is implemented.
module AfterInitialize
module ClassMethods
def call(_)
v = super
v.after_initialize
v
end
end
end
The class methods module defines the call method.
module AfterInitialize
module ClassMethods
def call(_)
v = super
v.after_initialize
v
end
end
end
The call method first calls super to get the default behavior, which returns the model instance with the hash of values.
module AfterInitialize
module ClassMethods
def call(_)
v = super
v.after_initialize
v
end
end
end
Then it calls the after_initialize method to run the initialize hooks on that instance.
module AfterInitialize
module ClassMethods
def call(_)
v = super
v.after_initialize
v
end
end
end
Then it returns the instance.
module AfterInitialize
module ClassMethods
def call(_)
v = super
v.after_initialize
v
end
end
end
By using a plugin to implement initialize hooks, Sequel makes it so only the users that actually need the initialize hooks pay the cost for them. The majority of users do not need initialize hooks and do not have to pay the performance cost for them.|Even for applications that use initialize hooks, they are often only used in a small number of models. With Sequel, you can load the plugin into only the models that need the initialize hooks, so it would not slow down initialization for other models.
class MyModel < Sequel::Model
plugin :after_initialize
end
By calling super to get the default behavior, it is easy to implement new features using plugins, as well as to extract rarely used features to plugins.|In both Sequel and Roda, most new features are implemented in plugins. Using plugins for most features does not just improve performance, it also saves memory by not allocating as many objects.
And that is another general optimization strategy in Ruby. Most objects you create in Ruby take time to allocate, time to mark during garbage collection, and time to free, even if they are not used. This includes all code that is required, even if the code is never used.|Both Sequel and Roda attempt to reduce object allocations. String allocations are probably the easiest to reduce,
you just need to use frozen string literals. Both Sequel and Roda have used frozen string literals since shortly after they were introduced in Ruby 2.3. Now, frozen string literals did not improve performance much when I added them to Sequel.
# frozen-string-literal: true
That was because for years before frozen string literals were introduced, I had stored all strings used to generate SQL in frozen constants, because that used to be the faster than using literal strings.
SELECT = 'SELECT'.freeze
SPACE = ' '.freeze
FROM = 'FROM'.freeze
def select_sql
sql = String.new
sql SELECT SPACE
sql literal(columns)
sql SPACE FROM SPACE
sql literal(table)
end
After Ruby 2.3 was in wide use, I removed the constants and inlined the strings, which improved SQL building by a few percent. This change made the code significantly easier to read. It also made it easier to see which strings could combined.
# frozen-string-literal: true
def select_sql
sql = String.new
sql "SELECT" " "
sql literal(columns)
sql " " "FROM" " "
sql literal(table)
end
Combining these strings reduced the number of string operations, further increasing SQL building performance.
# frozen-string-literal: true
def select_sql
sql = String.new
sql "SELECT "
sql literal(columns)
sql " FROM "
sql literal(table)
end
Sequel tries to improve performance by reducing hash allocations. Sequel used to have code like this in many methods, where the default argument value is a hash.
class Sequel::Dataset
def union(dataset, opts={})
compound_clone(:union, dataset, opts)
end
end
The problem with this style is that every call to this method with only a single argument allocates a hash. While allocating a single hash does not sound bad, when many methods do this, you can end up with a lot of unnecessary hashes being allocated.
class Sequel::Dataset
def union(dataset, opts={})
compound_clone(:union, dataset, opts)
end
end
So Sequel started using a empty frozen hash constant, named OPTS.
class Sequel::Dataset
OPTS = {}.freeze
def union(dataset, opts={})
compound_clone(:union, dataset, opts)
end
end
OPTS is used as the default value for most arguments that expect a hash. Using the frozen OPTS hash is almost twice as fast as allocating a new hash.
class Sequel::Dataset
OPTS = {}.freeze
def union(dataset, opts=OPTS)
compound_clone(:union, dataset, opts)
end
end
To save allocations, Sequel often passes the opts hash from one method directly to another method.
class Sequel::Dataset
OPTS = {}.freeze
def union(dataset, opts=OPTS)
compound_clone(:union, dataset, opts)
end
end
Now, why do Sequel and Roda both use option hashes instead of keyword arguments? There are a few reasons for that, but one reason is performance.
From a performance standpoint, keyword arguments perform better than option hashes in simple cases.
# Faster # Slower
def a(b: nil) def a(opts=OPTS)
b opts[:b]
end end
a(b: 1) a(b: 1)
When you are specifying the keyword argument in the method and calling the method with a keyword argument, using a keyword argument is faster.
# Faster # Slower
def a(b: nil) def a(opts=OPTS)
b opts[:b]
end end
a(b: 1) a(b: 1)
However, keyword arguments perform substantially worse if you are using keyword splats, either when using a keyword splat as a method argument,
# Slower # Faster
def a(**opts) def a(opts=OPTS)
opts[:b] opts[:b]
end end
a(b: 1) a(b: 1)
when using a keyword splat when calling a method,
# Slower! # Faster
def a(b: nil) def a(opts=OPTS)
b opts[:b]
end end
a(**hash) a(hash)
or especially when using a keyword splat both when calling the method and a keyword splat as a method argument.
# Slower!! # Faster
def a(**opts) def a(opts=OPTS)
opts[:b] opts[:b]
end end
a(**hash) a(hash)
If you want to write a method named foo that delegates keyword arguments to a method named bar, the obvious, simple, and maintainable approach of using keyword splats is many times slower than the optimal approach.
# Slow!
def foo(**opts)
bar(**opts)
end
def bar(c: nil, d: nil, e: nil)
c; d; e
end
For good performance, you have to take every keyword argument supported by method bar and make it a keyword argument of method foo.
# Fast
def foo(c: nil, d: nil, e: nil)
bar(c: c, d: d, e: e)
end
def bar(c: nil, d: nil, e: nil)
c; d; e
end
You also need to explicitly pass each keyword argument when calling bar from foo. This approach makes maintenance more cumbersome.
def foo(c: nil, d: nil, e: nil)
bar(c: c, d: d, e: e)
end
def bar(c: nil, d: nil, e: nil)
c; d; e
end
Every time you add a keyword argument to bar,
def foo(c: nil, d: nil, e: nil)
bar(c: c, d: d, e: e)
end
def bar(c: nil, d: nil, e: nil, f: nil)
c; d; e; f
end
You need to add the keyword argument to foo. Oops, looks like that is not correct.
def foo(c: nil, d: nil, e: nil, f: nil)
bar(c: c, d: d, e: e)
end
def bar(c: nil, d: nil, e: nil, f: nil)
c; d; e; f
end
You need to make sure to also add it when calling bar from foo.
def foo(c: nil, d: nil, e: nil, f: nil)
bar(c: c, d: d, e: e, f: f)
end
def bar(c: nil, d: nil, e: nil, f: nil)
c; d; e; f
end
If you change the default value for a keyword argument in bar,
def foo(c: nil, d: nil, e: nil, f: nil)
bar(c: c, d: d, e: e, f: f)
end
def bar(c: nil, d: nil, e: 2, f: nil)
c; d; e; f
end
you need to make the same change in foo.
def foo(c: nil, d: nil, e: 2, f: nil)
bar(c: c, d: d, e: e, f: f)
end
def bar(c: nil, d: nil, e: 2, f: nil)
c; d; e; f
end
In general, this approach makes maintenance more difficult and it increases complexity. When you have many methods that delegate option hashes, switching to this approach for keyword arguments is undesireable. I like optimizing code, but not enough to switch to this approach.
def foo(c: nil, d: nil, e: 2, f: nil)
bar(c: c, d: d, e: e, f: f)
end
def bar(c: nil, d: nil, e: 2, f: nil)
c; d; e; f
end
Especially since this approach is still slower then using an option hash if you have to splat an existing hash when calling foo.
def foo(c: nil, d: nil, e: 2, f: nil)
bar(c: c, d: d, e: e, f: f)
end
def bar(c: nil, d: nil, e: 2, f: nil)
c; d; e; f
end
foo(**hash)
The reason keyword splats are slow is that they allocate hashes.
def kws(**kw) end
def kw(a: nil) end
h = {a: nil}
Passing no arguments to a method that accepts an optional keyword argument does not allocate a hash.
def kws(**kw) end
def kw(a: nil) end
h = {a: nil}
kw # 0 hashes
Passing no arguments to a method that uses a keyword argument splat allocates one hash.
def kws(**kw) end
def kw(a: nil) end
h = {a: nil}
kw # 0 hashes
kws # 1 hash
Passing a keyword splat to a method that accepts an optional keyword argument allocates one to three hashes depending on Ruby version.
def kws(**kw) end
def kw(a: nil) end
h = {a: nil}
kw # 0 hashes
kws # 1 hash
kw(**h) # 1-3 hashes
Passing a keyword splat to a method that uses a keyword argument splat allocates two to four hashes depending on Ruby version.
def kws(**kw) end
def kw(a: nil) end
h = {a: nil}
kw # 0 hashes
kws # 1 hash
kw(**h) # 1-3 hashes
kws(**h) # 2-4 hashes
After that extended detour into keyword arguments, let me discuss reducing proc allocations. In general in performance sensitive code, you should avoid allocating procs that are not needed as closures.
Here is a simplified example from Roda’s indifferent params plugin. One thing to notice about this proc is that it does not have any dependencies on the surrounding scope. The proc does not access any instance variables.
def indifferent_params
Hash.new { |h, k| h[k.to_s] if k.is_a?(Symbol) }
end
The only local variables accessed are the arguments that are yielded to the proc.
def indifferent_params
Hash.new { |h, k| h[k.to_s] if k.is_a?(Symbol) }
end
The only methods called inside the proc are called on those local variables.
def indifferent_params
Hash.new { |h, k| h[k.to_s] if k.is_a?(Symbol) }
end
This proc can be extracted to a constant,
IND = proc { |h, k| h[k.to_s] if k.is_a?(Symbol) }
def indifferent_params
Hash.new(&IND)
end
and then passed as a block argument to Hash.new. Moving the block to a constant makes this code over 3 times faster.|Extracting objects to constants if the values do not depend on runtime state does not apply just to procs. It applies to most object types. But it is especially beneficial for procs as procs are heavy to allocate.
IND = proc { |h, k| h[k.to_s] if k.is_a?(Symbol) }
def indifferent_params
Hash.new(&IND)
end
If you are not using the proc as a block, and just calling it using the call method, you may be able to avoid allocating procs completely. |For example, Sequel datasets support a row proc, which is a callable object called with each hash retreived from the database. Originally, Sequel::Model used this approach for setting the dataset row proc, where self was the model class.
@dataset.row_proc = proc { |r| self.load(r) }
With this approach, every time the row proc was called, it took the row and passed it to the model class’s load method, causing an additional indirection for every row returned by Sequel.
@dataset.row_proc = proc { |r| self.load(r) }
I guessed that I could improve performance by aliasing the load method to call.
@dataset.row_proc = proc { |r| self.load(r) }
class Sequel::Model
alias call load
end
then assigning the model class itself as the dataset’s row_proc. This did turn out to be measurably faster, and is the reason that call is the method used to create new model objects retrieved from the database.
@dataset.row_proc = self
class Sequel::Model
alias call load
end
This brings me to another general optimization principle. To the extent that you can, in performance sensitive code, minimize the amount of indirection, as indirection generally results in slower code.
Sequel has numerous places where it uses objects that respond to call and wants to use the fastest implementation possible, which is generally the approach with the least indirection. Many of these cases are used to convert strings retrieved from the database to the appropriate ruby types.
If you need a callable for converting a string to an integer, it may be fairly natural to use a lambda. Sequel previously used something like this for type conversion.
integer = lambda { |str| Integer(str) }
If you look at this method, you see that it is calling the Integer method inside the lambda, which is another indirection.
integer = lambda { |str| Integer(str) }
So it may make sense to create a Method object for the Integer method. Method objects respond to call just as lambdas do. And it turns out that using a Method object is about 10% faster. But you can still do better than that.
integer = lambda { |str| Integer(str) }
integer = Kernel.method(:Integer)
It’s actually faster to create a plain object,
integer = lambda { |str| Integer(str) }
integer = Kernel.method(:Integer)
integer = Object.new
and then define a singleton call method on the object. This is faster than using the Method object by almost 10%.
integer = lambda { |str| Integer(str) }
integer = Kernel.method(:Integer)
integer = Object.new
def integer.call(str) Integer(str) end
However, notice that you still have indirection where you are calling the Integer method from inside the call method. It would probably go faster if you could remove the indirection.
integer = lambda { |str| Integer(str) }
integer = Kernel.method(:Integer)
integer = Object.new
def integer.call(str) Integer(str) end
It turns out that you can avoid the indirection in this case, by aliasing the Integer method to call and making the call method public. This is over 10% faster than the indirect call, and about 37% faster than the original approach of calling the Integer method inside a lambda.|I made this change in Sequel fairly recently, and using this approach for faster callables sped up some benchmarks of Sequel’s SQLite adapter by over 10%.
integer = lambda { |str| Integer(str) }
integer = Kernel.method(:Integer)
integer = Object.new
def integer.call(str) Integer(str) end
class integer
alias call Integer
public :call
end
In the last example, we saw that calling a method defined with def is faster than calling a lambda. Similarly, how you define a method in Ruby can affect the performance of the method.
Let’s say you have a method foo that returns 1. In most cases, you would use def to define this method, as in this example.
def foo
1
end
Now, you could define the method by passing a block to define_method. One of the reasons this is not typically done,
def foo
1
end
define_method(:foo) do
1
end
is that calling the method defined with define_method is about 50% slower than calling the method defined with def. So in general, you want to prefer defining methods with def.
def foo
1
end
define_method(:foo) do
1
end
However, when you need to define methods at runtime, it can be challenging to use def. For one, in order to use def to define methods at runtime, you also need to use eval, which can have security implications.
One place where Sequel dynamically defines methods is for getter and setter methods for model columns. The approach shown here results in methods that are the fastest to call, using class_eval and def.
columns.each do |column|
class_eval("def #{column}; @values[:#{column}] end")
class_eval("def #{column}=(v) @values[:#{column}] = v end")
end
For a simple column such as name,
columns.each do |column|
# column # => "name"
class_eval("def #{column}; @values[:#{column}] end")
class_eval("def #{column}=(v) @values[:#{column}] = v end")
end
this approach works fine.
columns.each do |column|
# column # => "name"
class_eval("def #{column}; @values[:#{column}] end")
# def name; @values[:name] end
class_eval("def #{column}=(v) @values[:#{column}] = v end")
# def name=(v) @values[:name] = v end
end
However, what if the column name has a space in it? If the column is named employee name with a space,
columns.each do |column|
# column # => "name"
# column # => "employee name"
class_eval("def #{column}; @values[:#{column}] end")
# def name; @values[:name] end
class_eval("def #{column}=(v) @values[:#{column}] = v end")
# def name=(v) @values[:name] = v end
end
you end up with this code.
columns.each do |column|
# column # => "name"
# column # => "employee name"
class_eval("def #{column}; @values[:#{column}] end")
# def name; @values[:name] end
# def employee name; @values[:employee name] end
class_eval("def #{column}=(v) @values[:#{column}] = v end")
# def name=(v) @values[:name] = v end
# def employee name=(v) @values[:employee name] = v end
end
Which does not work as this is a SyntaxError. And it is possible if an attacker has control over the column names, that this can be a remote code execution vulnerability.
columns.each do |column|
# column # => "name"
# column # => "employee name"
class_eval("def #{column}; @values[:#{column}] end")
# def name; @values[:name] end
# def employee name; @values[:employee name] end
class_eval("def #{column}=(v) @values[:#{column}] = v end")
# def name=(v) @values[:name] = v end
# def employee name=(v) @values[:employee name] = v end
end
If you want to be safe, you need to use define_method to define the column getters and setters. This is unfortunate as the vast majority of cases could be handled correctly and faster using def instead of define_method.
columns.each do |column|
column = column.to_sym
define_method(column) do
@values[column]
end
define_method(:"#{column}=") do |v|
@values[column] = v
end
end
What Sequel actually does is attempt to get the best of both worlds.
columns, bad_columns = columns.partition do |x|
/\A[A-Za-z][A-Za-z0-9]*\z/.match(x.to_s)
end
It partitions the column names to separate the good column names from the bad column names.
columns, bad_columns = columns.partition do |x|
/\A[A-Za-z][A-Za-z0-9]*\z/.match(x.to_s)
end
For the good column names that can be valid literal method names, Sequel uses def to define them for maximum performance. For the bad column names that cannot be valid literal method names, Sequel uses define_method so that calling the methods still works if you use send.
columns, bad_columns = columns.partition do |x|
/\A[A-Za-z][A-Za-z0-9]*\z/.match(x.to_s)
end
This is another general optimization principle that both Sequel and Roda use. Let’s say you have a fast approach that works for simple cases, but that fails in more complex cases. Assuming the simple case is more common than the complex case, you can speed up the code by separating the two cases, using the fast approach for the simple cases, and using the slow approach for the complex cases.
In general both Sequel and Roda have a preference for def over define_method in performance sensitive code. However, there is one case where define_method is preferred for performance reasons.
Assume you have a class method that defines an instance method.
def def_numbers(first, last)
class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
end
The class method takes two integer arguments,
def def_numbers(first, last)
class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
end
and defines an instance method named numbers that will return a frozen array created from the range between two arguments. The performance issue with using class_eval and def is that every time the numbers method is called, it needs to recompute the array.
def def_numbers(first, last)
class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
end
It is faster to compute this array up front.
def def_numbers(first, last)
#class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
array = (first..last).to_a.freeze
end
Then you can use define_method to define the instance method.
def def_numbers(first, last)
#class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
array = (first..last).to_a.freeze
define_method(:numbers) do
array
end
end
When the instance method is defined this way, it can return the array that was created when the class method was called, which is much faster than recomputing the array.
def def_numbers(first, last)
#class_eval("def numbers; (#{first}..#{last}).to_a.freeze end")
array = (first..last).to_a.freeze
define_method(:numbers) do
array
end
end
The basic principle here for performance is to prefer def over define_method for definining methods as they are faster to call,
unless you can access local variables in the surrounding scope to avoid computation inside the method.
Related to this, if you are accepting blocks and storing them, and later using instance exec to execute them on instances of a class, it is faster to create an instance method using define_method, and then call that method on the instances of the class.
Let’s implement a before hook to demonstrate this idea. Here you have a before class method that takes a block, and a before instance method that will execute all the blocks passed to the class method in the context of the instance.
def self.before(&block)
end
def before
end
One simple approach to this is to store each block in an instance variable in the class.
def self.before(&block)
before_hooks block
end
def before
end
Then in the before instance method, iterate over the array of blocks and instance exec each one. While this is a simple approach, it is also slow, partly because instance_exec creates a singleton class for the instance. It is faster to use methods.
def self.before(&block)
before_hooks block
end
def before
self.class.before_hooks.each { |b| instance_exec(&b) }
end
You start by selecting a method name for each block, based on the position in the before hooks array.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
end
def before
end
You then pass the block to define_method to create an instance method.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
end
def before
end
Then you add that method name to the array of before hooks
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
end
def before
end
In the instance method, you iterate over the array of method names, then use send to call each method. This is faster, but you can still do better.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
end
def before
self.class.before_hooks.each { |m| send(m) }
end
Since you know which methods will be executed, you can define the before instance method using class eval and def. This is faster as it avoids the need to call each on the array. Each method call is faster since you are calling it directly instead of indirectly via send.|This approach is pretty close to optimal. But if there is a only a single before hook, which is a relatively common case, you can do a little bit better.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
class_eval("def before; #{before_hooks.join(';')} end")
end
def before
end
You check if there is more than one before hook method defined.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
end
end
def before
end
If so, you define the method as you did before.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
end
end
def before
end
But if there is only a single before hook method defined, you alias before to the before hook method, which saves a method call at runtime.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
def before
end
You still want to keep the empty before instance method defined, so if that no before hooks are added, everything still works.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
def before
end
This approach for defining methods for hooks instead of using instance_exec is over twice as fast, mostly because it avoids a lot of internal indirection. Unfortunately, switching from instance_exec to define_method presents backwards compatibility issues.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
def before
end
If you pass a block that accepts an argument to the before method, this will work fine if you use instance_exec, but will cause an ArgumentError at runtime if you switch to define_method. Thankfully, you can work around this problem.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
before { |x| }
You check the arity of the block. If the block requires an argument,
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
unless block.arity == 0 || block.arity == -1
end
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
you assign the block to a different variable,
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
unless block.arity == 0 || block.arity == -1
b = block
end
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
Then you define a new block that accepts no arguments, and calls instance_exec with the previous block. I used this approach recently in Roda, when I switched from using instance_exec to using define_method for handling many blocks. This allowed me to keep backwards compatibility, but speed up the common case of route dispatching by over 60%.
def self.before(&block)
meth = :"_before_hook_#{before_hooks.length}"
unless block.arity == 0 || block.arity == -1
b = block
block = lambda { instance_exec(&b) }
end
define_method(meth, &block)
before_hooks meth
if before_hooks.length > 1
class_eval("def before; #{before_hooks.join(';')} end")
else
class_eval("alias before #{before_hooks.first}")
end
end
One of the best places to start optimizing is inside any inner loops. Even small improvements inside inner loops can result in significant improvements if there are a lot of iterations.
I am going to use an actual optimization taken from Sequel’s SQLAnywhere adapter as an example. The SQLAnywhere adapter was submitted via a pull request,
and this was the function for returning rows.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
execute(sql) do |rs|
max_cols = db.api.sqlany_num_cols(rs)
col_map = {}
max_cols.times do |cols|
col_map[db.api.sqlany_get_column_info(rs, cols)[2]] =
output_identifier(db.api.sqlany_get_column_info(rs, cols)[2])
end
@columns = col_map.values
convert = (convert_smallint_to_bool and db.convert_smallint_to_bool)
while db.api.sqlany_fetch_next(rs) == 1
max_cols = db.api.sqlany_num_cols(rs)
h2 = {}
max_cols.times do |cols|
h2[col_map[db.api.sqlany_get_column_info(rs, cols)[2]]||db.api.sqlany_get_column_info(rs, cols)[2]] =
cps[db.api.sqlany_get_column_info(rs, cols)[4]].nil? ?
db.api.sqlany_get_column(rs, cols)[1] :
db.api.sqlany_get_column_info(rs, cols)[4] != 500 ?
cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
convert ? cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
db.api.sqlany_get_column(rs, cols)[1]
end
yield h2
end unless rs.nil?
end
self
end
This is the inner loop, called for every column of every row. Even this is a lot of code, but I will only be focusing on a few parts. One thing that I found almost amusing about this code,
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
execute(sql) do |rs|
max_cols = db.api.sqlany_num_cols(rs)
col_map = {}
max_cols.times do |cols|
col_map[db.api.sqlany_get_column_info(rs, cols)[2]] =
output_identifier(db.api.sqlany_get_column_info(rs, cols)[2])
end
@columns = col_map.values
convert = (convert_smallint_to_bool and db.convert_smallint_to_bool)
while db.api.sqlany_fetch_next(rs) == 1
max_cols = db.api.sqlany_num_cols(rs)
h2 = {}
max_cols.times do |cols|
h2[col_map[db.api.sqlany_get_column_info(rs, cols)[2]]||db.api.sqlany_get_column_info(rs, cols)[2]] =
cps[db.api.sqlany_get_column_info(rs, cols)[4]].nil? ?
db.api.sqlany_get_column(rs, cols)[1] :
db.api.sqlany_get_column_info(rs, cols)[4] != 500 ?
cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
convert ? cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
db.api.sqlany_get_column(rs, cols)[1]
end
yield h2
end unless rs.nil?
end
self
end
was this nesting of ternery operators 3 levels deep, with no parentheses. Now, that is not my prefered coding style. That was not the reason for the performance issue in this code, though. The reason this code was slow,
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
execute(sql) do |rs|
max_cols = db.api.sqlany_num_cols(rs)
col_map = {}
max_cols.times do |cols|
col_map[db.api.sqlany_get_column_info(rs, cols)[2]] =
output_identifier(db.api.sqlany_get_column_info(rs, cols)[2])
end
@columns = col_map.values
convert = (convert_smallint_to_bool and db.convert_smallint_to_bool)
while db.api.sqlany_fetch_next(rs) == 1
max_cols = db.api.sqlany_num_cols(rs)
h2 = {}
max_cols.times do |cols|
h2[col_map[db.api.sqlany_get_column_info(rs, cols)[2]]||db.api.sqlany_get_column_info(rs, cols)[2]] =
cps[db.api.sqlany_get_column_info(rs, cols)[4]].nil? ?
db.api.sqlany_get_column(rs, cols)[1] :
db.api.sqlany_get_column_info(rs, cols)[4] != 500 ?
cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
convert ? cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
db.api.sqlany_get_column(rs, cols)[1]
end
yield h2
end unless rs.nil?
end
self
end
was these calls to db.api.sqlany_get_column_info with the same 2 arguments. This method is called up to 5 times in the inner loop. This method returns an array, and only 2 elements of this array are needed, the name of the column and the type of the column. Note that the names of the columns and types of the columns are the same for each row in the result set, as such this method does not need to be called in the inner loop at all.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
execute(sql) do |rs|
max_cols = db.api.sqlany_num_cols(rs)
col_map = {}
max_cols.times do |cols|
col_map[db.api.sqlany_get_column_info(rs, cols)[2]] =
output_identifier(db.api.sqlany_get_column_info(rs, cols)[2])
end
@columns = col_map.values
convert = (convert_smallint_to_bool and db.convert_smallint_to_bool)
while db.api.sqlany_fetch_next(rs) == 1
max_cols = db.api.sqlany_num_cols(rs)
h2 = {}
max_cols.times do |cols|
h2[col_map[db.api.sqlany_get_column_info(rs, cols)[2]]||db.api.sqlany_get_column_info(rs, cols)[2]] =
cps[db.api.sqlany_get_column_info(rs, cols)[4]].nil? ?
db.api.sqlany_get_column(rs, cols)[1] :
db.api.sqlany_get_column_info(rs, cols)[4] != 500 ?
cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
convert ? cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
db.api.sqlany_get_column(rs, cols)[1]
end
yield h2
end unless rs.nil?
end
self
end
db.api.sqlany_get_column_info(rs, cols)These calls are to db.api.sqlany_get_column with the same 2 arguments. This method also returns an array, and only the second element of the array is needed, which is the value of the column in the current row. This method, while it appears 4 times in the inner loop, is only ever called once, depending on which branch each ternery operator takes. This method does depend on the current position in the result set, and as such it does need to be called in the inner loop.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
execute(sql) do |rs|
max_cols = db.api.sqlany_num_cols(rs)
col_map = {}
max_cols.times do |cols|
col_map[db.api.sqlany_get_column_info(rs, cols)[2]] =
output_identifier(db.api.sqlany_get_column_info(rs, cols)[2])
end
@columns = col_map.values
convert = (convert_smallint_to_bool and db.convert_smallint_to_bool)
while db.api.sqlany_fetch_next(rs) == 1
max_cols = db.api.sqlany_num_cols(rs)
h2 = {}
max_cols.times do |cols|
h2[col_map[db.api.sqlany_get_column_info(rs, cols)[2]]||db.api.sqlany_get_column_info(rs, cols)[2]] =
cps[db.api.sqlany_get_column_info(rs, cols)[4]].nil? ?
db.api.sqlany_get_column(rs, cols)[1] :
db.api.sqlany_get_column_info(rs, cols)[4] != 500 ?
cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
convert ? cps[db.api.sqlany_get_column_info(rs, cols)[4]].call(db.api.sqlany_get_column(rs, cols)[1]) :
db.api.sqlany_get_column(rs, cols)[1]
end
yield h2
end unless rs.nil?
end
self
end
db.api.sqlany_get_column(rs, cols)[1]Here is the final code after optimization.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
This highlighted section is the inner loop. One thing to note about this inner loop is that all operations inside it are on local variables.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
To make that possible, we need to set the local variables the inner loop uses before the start of the inner loop. This way we do not have to call methods or reference instance variables to get this data inside the inner loop. It may seem like this is not that important, but if you are retrieving 10,000 rows and each row has 100 columns, defining these 2 local variables outside the inner loop and using them inside the inner loop saves 2 million method calls.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
api = db.api
max = col_infos.length
This is another general Ruby optimization principle, which is to prefer using local variables whenever possible, and especially in inner loops.
Local variable access is faster than instance variable access.
Local variable access is faster than constant access.
Local variable access is faster than method calls.
Local variables are faster than instance variables, constants, and method calls because they minimize the amount of internal indirection.
Whenever you can store the result of an instance variable, constant, or method call in a local variable before a loop, and access the local variable inside the loop, doing so will improve performance.
Getting back to the the inner loop optimization example, that sqlany_get_column_info method that was previously called up to 5 times in the inner loop is now no longer called inside the inner loop, it is only called one time per column before the inner loop to get the name and type of the column.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
db.api.sqlany_get_column_info(rs, cols)We use the type of the column to get a convertor object to convert the database value to the appropriate ruby type.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
cp = if type == 500
cps[500] if convert
else
cps[type]
end
We store the column name and convertor for each column in an array of column infos.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
col_infos [output_identifier(name), cp]
The first line inside the inner loop retrieves the column name and convertor object from that array of column infos.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
In the next line, we call the api.sqlany_get_column method to get the value of the column.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
In the third line, if there is a convertor and the value of the column is not nil, we call the convertor with the value to get the appropriate ruby object.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
We then set that object for the column name in the hash.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
One thing to note here is the deliberate use of while instead of using col_infos.each. Inner loops like this one are one of the few places where it makes sense to use while instead of each, as that change alone can improve real world performance by a couple percent. Using each for inner loops can hurt performance because it requires a separate stack frame to be pushed and popped for each iteration.
def fetch_rows(sql)
db = @db
cps = db.conversion_procs
api = db.api
execute(sql) do |rs|
convert = convert_smallint_to_bool
col_infos = []
api.sqlany_num_cols(rs).times do |i|
_, _, name, _, type = api.sqlany_get_column_info(rs, i)
cp = if type == 500
cps[500] if convert
else
cps[type]
end
col_infos [output_identifier(name), cp]
end
self.columns = col_infos.map(&:first)
max = col_infos.length
if rs
while api.sqlany_fetch_next(rs) == 1
i = -1
h = {}
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
yield h
end
end
end
self
end
while (i+=1) max
name, cp = col_infos[i]
v = api.sqlany_get_column(rs, i)[1]
h[name] = cp && v ? cp.call(v) : v
end
I am going to change pace from the lower level optimization techniques I have been focusing on so far, and discuss something that actually becomes more important as your application becomes larger. And that is choosing faster algorithms, such as the algorithm used to route web requests.
For hello world benchmarks with a single route, the routing algorithm does not matter, and performance only depends on the overhead of the routing implementation. Roda has very low overhead, so it does well in the single route case.
However, when you have thousands of routes in your web application, the algorithm you use for routing becomes much more important than the amount of overhead in the routing implementation.
For years before working on Roda, I used Sinatra for most web development. One issue with Sinatra is that the time taken to route requests is proportional to the number of routes.
A simplified version of Sinatra’s router looks like this.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
Sinatra first gets an array of all routes for the request method, such as GET or POST.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
Sinatra iterates over each of these routes.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
Sinatra checks if the current route matches the request path.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
If so, Sinatra takes the unbound method for the route, creates a Method object, and calls the Method object to get the rack response array.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
Then, like Roda, Sinatra uses throw to return the rack response array to the webserver.
def route
routes = self.class.routes[@request.request_method]
routes.each do |pattern, unbound_method|
if match(pattern, @request.path)
res = unbound_method.bind(self).call
throw :halt, res
end
end
end
This works fine if you have a small number of routes. But if you have thousands of routes, Sinatra applications can spend a large proportion of request time iterating over the array of routes looking for a matching route, instead of running the user’s code. This is one reason Sinatra is rarely used for applications with a large number of routes.
Roda uses a routing tree, where once you take one branch of the tree, you ignore other branches. This results in roughly O(log(n)) performance for routing in most web applications.
A brief example of this is the following routing tree.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
After Roda yields control to the route block, the r.on method is called with the string foo, which checks to see if the first segment of the request path is foo.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
If so, then the block yields, and only routes inside that block are considered. All routes for other initial segments are no longer considered.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
If the first segment of the path is not foo, the r.on method returns without yielding to the block.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
Then control continues with the next routing method call.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
So in Roda that there is a linear search of the initial segments of the tree. Now, for most routing trees, that is not a major issue.
Roda.route do |r|
r.on "foo" do
# /foo branch
end
r.on "bar" do
# /bar branch
end
# ...
end
However, if you had a completely flat URL structure where all initial path segments were distinct, then Roda’s routing tree would devolve back to linear search behavior, similar to Sinatra.|I did not consider that acceptable, so for that reason and for general code organization, Roda has offered multi_route plugin since the initial release.
Here’s a similar routing tree using Roda’s multi_route plugin.
Roda.plugin :multi_route
Roda.route('foo') do |r|
# /foo branch
end
Roda.route('bar') do |r|
# /bar branch
end
# ...
Roda.route do |r|
r.multi_route
end
The main difference here are the routing trees for the foo initial segment and bar initial segment are outside the main routing tree, and would usually be stored in separate files. Roda takes all of these initial segments and builds a regular expression.
Roda.plugin :multi_route
Roda.route('foo') do |r|
# /foo branch
end
Roda.route('bar') do |r|
# /bar branch
end
# ...
Roda.route do |r|
r.multi_route
end
In the main routing tree, the r.multi_route method is called, which will use that regular expression to match against all initial segments that have been registered, and then dispatch to the appropriate routing block.
Roda.plugin :multi_route
Roda.route('foo') do |r|
# /foo branch
end
Roda.route('bar') do |r|
# /bar branch
end
# ...
Roda.route do |r|
r.multi_route
end
This allows for roughly O(log(n)) routing performance for the initial route segments. The multi_route plugin also supports namespaces, which allows for O(log(n)) routing performance at all levels of the routing tree.
And that is great, but what if you could make routing performance be O(1), so routing had roughly the same performance regardless of the number of routes?
Roda supports that using the static routing plugin. This plugin allows for O(1) routing for statically defined routes. This is the fastest way to route requests, but unfortunately you lose the main advantage of Roda, which is the ability to operate on a request at any point during routing.
Roda.plugin :static_routing
Roda.static_get('/foo') do |r|
# GET /foo
end
Roda.static_get('/bar') do |r|
# GET /bar
end
# ...
Roda.route do |r|
end
With the static routing plugin, you need to provide the full path of the request to match against when specifying the route for that block. Roda will put all of these static route paths in a hash.
Roda.plugin :static_routing
Roda.static_get('/foo') do |r|
# GET /foo
end
Roda.static_get('/bar') do |r|
# GET /bar
end
# ...
Roda.route do |r|
end
Before the normal routing tree is called, Roda will check if the path of the request is in hash of static route paths. If so, it will dispatch to the appropriate route block.
Roda.plugin :static_routing
Roda.static_get('/foo') do |r|
# GET /foo
end
Roda.static_get('/bar') do |r|
# GET /bar
end
# ...
Roda.route do |r|
end
When using the static_routing plugin, the difference in routing speed between 10 routes and 10,000 routes,
is around 15%. The TechEmpower benchmarks for Roda use the static_routing plugin to get the maximum performance, even though they only have 6 routes.
So Roda’s static_routing plugin gives you O(1) routing, but you have to give up the main advantage of Roda. Wouldn’t it be great to keep O(1) routing, but still be able to operate on the request at any point during routing? I thought it would.
So recently I added the hash_routes plugin to Roda, which combines the O(1) routing of the static_routing plugin with the ability to operate on a request at any point during routing.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
# /foo branch
r.hash_routes
end
is 'foo/bar' do |r|
# /foo/bar path
end
end
Roda.route do |r|
r.hash_routes
end
You call the hash_routes class method with a block that looks similar to a standard Roda routing block. In this case, hash_routes is called without an argument, so the block given will set routes in the default namespace.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
# /foo branch
r.hash_routes
end
is 'foo/bar' do |r|
# /foo/bar path
end
end
Roda.route do |r|
r.hash_routes
end
Inside the block, you use the on method to match branches, like Roda’s standard branch matching.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
# /foo branch
r.hash_routes
end
is 'foo/bar' do |r|
# /foo/bar path
end
end
Roda.route do |r|
r.hash_routes
end
Inside the block, you use the is method to match full paths, like Roda’s standard path matching. So the hash_routes plugin should feel natural to most Roda users, even though under the hood it operates differently, with O(1) dispatching to each of the routes inside the hash_routes block .
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
# /foo branch
r.hash_routes
end
is 'foo/bar' do |r|
# /foo/bar path
end
end
Roda.route do |r|
r.hash_routes
end
Using the hash_routes plugin keeps the primary advantage of Roda, which is the ability to operate on requests at any point during routing.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
Let’s say the path we are trying to route is /foo/123/bar. I think most applications have routes like this, combining static segments such as foo and bar and dynamic segments such as the 123, where 123 is the id of the specific foo you are requesting.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/foo/123/bar"
The main route block calls the r.hash_routes method without an argument, which will perform an O(1) dispatch to the matching route in the default namespace, if such a route exists.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/foo/123/bar"
Because the first segment in the request path is foo, the r.hash_routes call will dispatch to the block specified by the on foo call here.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/foo/123/bar"
That on foo call will extract the foo segment from the path, leaving the remaining path as /123/bar.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/123/bar"
The on foo call will yield the request to this block, which operates like a standard Roda routing tree. You can operate on the request at any point inside this block.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/123/bar"
The r.on Integer call here
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/123/bar"
will extract the 123 segment from the remaining path, leaving the remaining path as /bar.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/bar"
It will yield the integer 123 to the block.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/bar"
We can look up the foo object with id 123, and store it in an instance variable.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/bar"
Then the r.hash_routes method is called with the symbol :foo, which will perform an O(1) dispatch to the matching route in the foo namespace, if such a route exists. The @foo instance variable you set in the line above will be available for all routes in the :foo namespace to use. We assume one of the routes in the :foo namespace will be bar.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
"/bar"
This approach does add a little complexity compared to Roda’s standard routing, but I think it is the most scalable design. It allows O(1) routing performance at each level of the routing tree, and still supports the ability to operate on requests at any point during routing, which is the main reason Roda applications tend to be simpler that applications developed in other frameworks.|In this example, we saw how hashes can be used to improve performance.
Roda.plugin :hash_routes
Roda.hash_routes do
on 'foo' do |r|
r.on Integer do |id|
@foo = Foo[id]
r.hash_routes(:foo)
end
end
end
Roda.route do |r|
r.hash_routes
end
Anytime you are repeatedly performing the same computation on the same inputs, using hashes to introduce caching can also yield large performance improvements.
In my experience, introducing caching has the highest ratio of percentage increase in performance to lines of code changed.
I was able to dramatically improve performance in Sequel by adding caching to the literalization of symbols. Sequel uses Ruby symbols to represent SQL identifiers, such as table names and column names.
The literalization process in Sequel takes a symbol as an argument
:column_name
and adds the literalized version of the symbol to the SQL being generated. How symbols are literalized depends on which database is being used, and how Sequel is configured.
:column_name
# => '"column_name"'
One of the reasons that literalizing symbols was slow in older versions of Sequel is that Sequel used special handling for symbols like this, allowing you to embed table names and column names in the same symbol.
:column_name
# => '"column_name"'
:table_name__column_name
Sequel would split this symbol into an SQL qualified identifier with a table name and column name.
:column_name
# => '"column_name"'
:table_name__column_name
# => '"table_name"."column_name"'
This required running regular expressions on all symbols to determine if they should be split, using this code. This feature is no longer on by default, but it is still supported for backwards compatibility.
def self.split_symbol(sym)
v = case s = sym.to_s
when /\A((?:(?!__).)+)__((?:(?!___).)+)___(.+)\z/
[$1.freeze, $2.freeze, $3.freeze].freeze
when /\A((?:(?!___).)+)___(.+)\z/
[nil, $1.freeze, $2.freeze].freeze
when /\A((?:(?!__).)+)__(.+)\z/
[$1.freeze, $2.freeze, nil].freeze
else
[nil, s.freeze, nil].freeze
end
v
end
Sequel used to spend almost half of the time generating SQL in this code. Because almost all applications use a fixed set of table names and column names, this was a natural place to introduce caching.
def self.split_symbol(sym)
v = case s = sym.to_s
when /\A((?:(?!__).)+)__((?:(?!___).)+)___(.+)\z/
[$1.freeze, $2.freeze, $3.freeze].freeze
when /\A((?:(?!___).)+)___(.+)\z/
[nil, $1.freeze, $2.freeze].freeze
when /\A((?:(?!__).)+)__(.+)\z/
[$1.freeze, $2.freeze, nil].freeze
else
[nil, s.freeze, nil].freeze
end
v
end
We start by creating a hash for the cache.
SPLIT_SYMBOL_CACHE = {}
def self.split_symbol(sym)
v = case s = sym.to_s
when /\A((?:(?!__).)+)__((?:(?!___).)+)___(.+)\z/
[$1.freeze, $2.freeze, $3.freeze].freeze
when /\A((?:(?!___).)+)___(.+)\z/
[nil, $1.freeze, $2.freeze].freeze
when /\A((?:(?!__).)+)__(.+)\z/
[$1.freeze, $2.freeze, nil].freeze
else
[nil, s.freeze, nil].freeze
end
v
end
First we modify the code to check if the symbol is already in the cache. If so, we use the already computed value.
SPLIT_SYMBOL_CACHE = {}
def self.split_symbol(sym)
unless v = Sequel.synchronize{SPLIT_SYMBOL_CACHE[sym]}
v = case s = sym.to_s
when /\A((?:(?!__).)+)__((?:(?!___).)+)___(.+)\z/
[$1.freeze, $2.freeze, $3.freeze].freeze
when /\A((?:(?!___).)+)___(.+)\z/
[nil, $1.freeze, $2.freeze].freeze
when /\A((?:(?!__).)+)__(.+)\z/
[$1.freeze, $2.freeze, nil].freeze
else
[nil, s.freeze, nil].freeze
end
end
v
end
Finally, if this is a new symbol not in the cache, after performing the computation, we need to store the computed value in the hash. Adding caching sped up this method over 10x, which sped up the generation of SQL for common datasets by up to 80%.
SPLIT_SYMBOL_CACHE = {}
def self.split_symbol(sym)
unless v = Sequel.synchronize{SPLIT_SYMBOL_CACHE[sym]}
v = case s = sym.to_s
when /\A((?:(?!__).)+)__((?:(?!___).)+)___(.+)\z/
[$1.freeze, $2.freeze, $3.freeze].freeze
when /\A((?:(?!___).)+)___(.+)\z/
[nil, $1.freeze, $2.freeze].freeze
when /\A((?:(?!__).)+)__(.+)\z/
[$1.freeze, $2.freeze, nil].freeze
else
[nil, s.freeze, nil].freeze
end
Sequel.synchronize{SPLIT_SYMBOL_CACHE[sym] = v}
end
v
end
One way to make it easier to use caching to improve performance is to use an approach I call globally frozen, locally mutable. With this approach, you freeze your global state that persists across requests, such as classes and other objects that can be accessed by multiple threads. However, local objects that are instantiated per request and not kept after the request remain mutable for ease of use.
The main reason I use this approach is for improved reliability, as this approach makes it much more difficult to introduce thread safety issues in applications.
But this approach can lead to improved performance. Because frozen objects cannot be modified, it means that they can be easily cached.
With this approach, frozen does not mean that all parts of objects are immutable. While that would be fine for reliability, it would not be great for performance.
To make this approach improve performance, you keep the object’s state immutable, but you allow the object to contain mutable hashes that are used for caching. In general you want to make sure these caches are thread safe, so access to them should be protected by a mutex.
Here is the initialize method for Sequel::Dataset.
def initialize(db)
@db = db
@opts = OPTS
@cache = {}
freeze
end
Sequel datasets keep their state in a frozen hash called opts.
def initialize(db)
@db = db
@opts = OPTS
@cache = {}
freeze
end
Each dataset has a cache that is not frozen. Access to this cache is performed through private methods that use a mutex to ensure thread safe access to the cache.
def initialize(db)
@db = db
@opts = OPTS
@cache = {}
freeze
end
Then the object itself is frozen, ensuring that the only part of the object that can be modifed is the cache.
def initialize(db)
@db = db
@opts = OPTS
@cache = {}
freeze
end
Sequel datasets use the cache extensively to improve performance. One case where there was an immediate substantial increase in performance is when I started caching the generated SQL for datasets.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
When a dataset is asked to generate the SQL query, it first checks if the SQL is already cached.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
If so, it returns the cached SQL, which even for the simplest datasets, is over 6x faster than regenerating the SQL.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
If the SQL is not cached, then Sequel must generate the SQL for the dataset.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
After Sequel has generated the SQL, it can determine whether or not is is possible to cache the SQL for the dataset. In some cases, it is not possible to cache the SQL, because the SQL could change depending on runtime state.|This is another example of separating the common case from the uncommon case when optimizing. In the common case, it is possible to cache the SQL, and doing so is much faster. In the uncommon case, caching is not possible, in which case checking the cache adds little overhead compared to generating the SQL.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
Assuming this is the common case, the generated SQL is stored in the cache, so that the next call to generate the SQL for this dataset will be able to benefit from the caching.
def select_sql
if sql = cache_get(:_select_sql)
return sql
end
sql = String.new
# ...
cache_set(:_select_sql, sql) if cache_sql?
sql
end
Another example of how Sequel uses caching is for caching intermediate datasets. Sequel datasets have a single_record method, which returns the first row in the dataset. This is how the single_record method looked a couple years ago, before I added caching to datasets.
def single_record
clone(:limit=>1).single_record!
end
This method first had to create a clone of the dataset to limit the dataset to one row, which added a little bit of overhead by itself.
def single_record
clone(:limit=>1).single_record!
end
After caching was added to datasets, I changed this to call a method named single_record_ds.
def single_record
_single_record_ds.single_record!
end
The single_record_ds method would check the cache and see if there was a cached dataset that was already limited to one row. If so, it would return the cached dataset, instead of allocating another dataset.
def single_record
_single_record_ds.single_record!
end
def _single_record_ds
cached_dataset(:_single_record_ds) do
clone(:limit=>1)
end
end
If there was no entry in the cache, it would call the block to get the dataset, and it would store the dataset the block returned in the cache.
def single_record
_single_record_ds.single_record!
end
def _single_record_ds
cached_dataset(:_single_record_ds) do
clone(:limit=>1)
end
end
After getting the dataset that has been limited to one row, single_record! is called to return the row. Assuming the dataset is in the cache, this turns out to be a large optimization. While saving the dataset allocation is only a small optimization, because the returned dataset will already have cached the generated SQL, this allows Sequel to skip the expensive step of generating the SQL, which improved performance of this method by over 30%.
def single_record
_single_record_ds.single_record!
end
def _single_record_ds
cached_dataset(:_single_record_ds) do
clone(:limit=>1)
end
end
In addition to using this approach to optimize many of Sequel’s internal methods, Sequel also automatically uses this optimization in metaprogramming methods it exposes to the user.
For many years, Sequel has supported the ability for model classes to add methods to the model’s dataset.
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
The dataset_module class method accepts a block, and module_evals the block in the context of a subclass of Module
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
This allows you to define methods inside the block, such as by_name to order the dataset by name,
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
and released to filter the dataset to only include albums that have been released.
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Once these methods are defined inside the dataset_module block, you can simplify code like this.
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Album.where(released: true).order(:name).first
You can replace the where call with the released method,
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Album.released.order(:name).first
and the order call with the by_name method. Now with older versions of Sequel, you would use this approach to make the code easier to read, and to DRY up code. However, it did not improve performance.
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Album.released.by_name.first
After adding dataset caching, I developed a way to dramatically speed up this code.
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Album.released.by_name.first
I added metaprogramming methods inside the dataset_module block. Inside of defining the by_name method with def,
class Album < Sequel::Model
dataset_module do
def by_name
order(:name)
end
def released
where(released: true)
end
end
end
Album.released.by_name.first
You call a method named order, which will define a method that calls the order method.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def
# order()
# end
def released
where(released: true)
end
end
end
Album.released.by_name.first
The first argument to order is the method name to define, in this case by_name.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# order()
# end
def released
where(released: true)
end
end
end
Album.released.by_name.first
All remaining arguments are passed to the order call.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# order(:name)
# end
def released
where(released: true)
end
end
end
Album.released.by_name.first
Similarly, you can define the released method by calling the where method with released as the first argument, and the hash with released true as the second argument.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# order(:name)
# end
where :released, released: true
# def released
# where(released: true)
# end
end
end
Album.released.by_name.first
The performance advantage of using these metaprogramming methods,
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# order(:name)
# end
where :released, released: true
# def released
# where(released: true)
# end
end
end
Album.released.by_name.first
is that these methods define methods that support caching automatically.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# cache{order(:name)}
# end
where :released, released: true
# def released
# cache{where(released: true)}
# end
end
end
Album.released.by_name.first
So the first time you call Album.released, you have to allocate a new dataset. But all subsequent calls return a cached dataset.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# cache{order(:name)}
# end
where :released, released: true
# def released
# cache{where(released: true)}
# end
end
end
Album.released.by_name.first
The first time you call by_name on that dataset, you have to allocate a new dataset. But all subsequent calls return a cached dataset.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# cache{order(:name)}
# end
where :released, released: true
# def released
# cache{where(released: true)}
# end
end
end
Album.released.by_name.first
The first time you call first on that dataset, you have to generate the SQL. But all subsequent calls use the cached SQL.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# cache{order(:name)}
# end
where :released, released: true
# def released
# cache{where(released: true)}
# end
end
end
Album.released.by_name.first
If you run this 100 times, due to caching, you only allocate 3 datasets and only have to generate the SQL once. This is way faster that the uncached approach, which would allocate 300 datasets and generate the SQL 100 times.
class Album < Sequel::Model
dataset_module do
order :by_name, :name # def by_name
# cache{order(:name)}
# end
where :released, released: true
# def released
# cache{where(released: true)}
# end
end
end
100.times { Album.released.by_name.first }
I used caching and a few other techniques I have discussed in this presentation while optimizing Roda’s string matching.
Roda was forked from another web framework named Cuba. At a point shortly after forking, this was the code Roda used to determine if a given string matched the next segment in the request path.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A\/(#{pattern})(\/|\z)/)
return false unless matchdata
path, *vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
The match_string method should return whether the next segment in the path matches the given string.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A\/(#{pattern})(\/|\z)/)
return false unless matchdata
path, *vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
The consume method is more general, matching regular expressions to the request path, and handling any captures so they can be yielded to the appropriate block.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A\/(#{pattern})(\/|\z)/)
return false unless matchdata
path, *vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
My first focus was to avoid as many allocations as I could in this code.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A\/(#{pattern})(\/|\z)/)
return false unless matchdata
path, *vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
The first change was modifying the first capture in the regular expression to include the preceding slash.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(\/|\z)/)
return false unless matchdata
path, *vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
We avoid the extra array allocation for the captures.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += "/#{path}"
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
Instead shifting off the first element of the array, which is the path with the preceding slash, which avoids the additional string allocation.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
The next change was to modify the regular expression to use a positive lookahead assertion instead of a capture to determine if the pattern was at the end of a segment.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(?=\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
This made it so we no longer need to pop the last element off the array of captured variables.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(?=\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = "#{vars.pop}#{matchdata.post_match}"
captures.push(*vars)
end
and we could avoid the allocation of the additional string by using post_match directly.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(?=\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = matchdata.post_match
captures.push(*vars)
end
Some profiling I did showed that generating a new regular expression every time consume was called was taking a large portion of the total time spent.
def match_string(str)
consume(Regexp.escape(str))
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(?=\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = matchdata.post_match
captures.push(*vars)
end
As almost all strings used for routing are static, I was able to dramatically speed up the match_string method by caching the generated regular expressions.
def match_string(str)
consume(self.class.cached_matcher(str){Regexp.escape(str)})
end
def consume(pattern)
matchdata = env[PATH_INFO].match(/\A(\/(?:#{pattern}))(?=\/|\z)/)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = matchdata.post_match
captures.push(*vars)
end
With a corresponding change to the consume method to use the regular expression directly instead of generating a new regular expression. Note that I could only make this behavior change to consume because consume was a private method.
def match_string(str)
consume(self.class.cached_matcher(str){Regexp.escape(str)})
end
def consume(pattern)
matchdata = env[PATH_INFO].match(pattern)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = matchdata.post_match
captures.push(*vars)
end
That brings me to another optimization principle, which is to keep most methods private. Only make a method public if it needs to be public. If a method is private, you are free to change its API to improve performance. Making a method public limits your optimization options.
So this is what Roda’s string matching code looked like in Roda 1.0.
def match_string(str)
consume(self.class.cached_matcher(str){Regexp.escape(str)})
end
def consume(pattern)
matchdata = env[PATH_INFO].match(pattern)
return false unless matchdata
vars = matchdata.captures
env[SCRIPT_NAME] += vars.shift
env[PATH_INFO] = matchdata.post_match
captures.push(*vars)
end
The consuming of patterns was further optimized before the release of Roda 2, avoiding the need to modify the rack environment completely, or do any operations on the array of captures.
def match_string(str)
consume(self.class.cached_matcher(str){Regexp.escape(str)})
end
def consume(pattern)
if matchdata = remaining_path.match(pattern)
@remaining_path = matchdata.post_match
@captures.concat(matchdata.captures)
end
end
Instead of using the rack environment to store the remaining path, I started storing the remaining path in an instance variable, and then during matching, we just need to update the remaining path instance variable with the part of the string after the match. String matching was further optimized later using another general optimization principle.
def match_string(str)
consume(self.class.cached_matcher(str){Regexp.escape(str)})
end
def consume(pattern)
if matchdata = remaining_path.match(pattern)
@remaining_path = matchdata.post_match
@captures.concat(matchdata.captures)
end
end
Which is to prefer string operations to regular expression operations in cases where you can perform the same operation, as string operations are faster.
So in Roda 3.0, the string matching code looked like this.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
We start by checking if the remaining path starts with the string prefixed with a slash.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
If so, we check next character in the string.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
If the next character in the string is a slash, then we have matched a whole segment.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
In that case, we update the remaining path to remove the segment we matched.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
If the last character is nil, then we have matched the final segment in the path
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
In that case, we set the remaining path to the empty string.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
If the match is some other character, that means we only matched a partial segment and not a whole segment, so it isn’t a true match. In that case, we return nil without updating the remaining path. We can omit the else clause in this case, as the behavior is the same.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
# else
# nil
end
end
end
The main remaining issue with this code are these two string allocations. Eliminating them would make the code even faster.
def match_string(str)
rp = @remaining_path
if rp.start_with?("/#{str}")
last = str.length + 1
case rp[last]
when "/"
@remaining_path = rp[last, rp.length]
when nil
@remaining_path = ""
end
end
end
So I recently did that.
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
I replaced the start_with call with an rindex call starting where we expect the end of the segment to be. This avoids allocating a new string for the segment preceded by a slash.
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
When checking for slashes, instead of retrieving the character and comparing it to the slash string, I call getbyte, and compare the result to the ASCII code for slash, which is 47. This is another general optimization principle,
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
Which is to prefer integer operations to string operations in cases where you can perform the same operation, as integer operations are faster.
I make the first when clause in first case statement handle the failure case, since that is more common than the success case when doing path matching.
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
I also cheat here and don’t use a method call to determine the proper end of the string, instead just using a number larger than any reasonable path length, since I want all remaining characters in the string.
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
All told, this is 10 to 20 percent faster than the approach used in Roda 3.0, and many times faster than the code before optimization.
def match_string(str)
rp = @remaining_path
length = str.length
match = case rp.rindex(str, length)
when nil
return
when 1
rp.getbyte(0) == 47
else
length == 0 && rp.getbyte(0) == 47
end
if match
length += 1
case rp.getbyte(length)
when 47
@remaining_path = rp[length, 100000000]
when nil
@remaining_path = ""
end
end
end
It is important to remember that optimization should be one of the last things you do.
First you make it work.
Then you make it correct.
Then you make it fun. This is Ruby after all, you gotta make it fun.
Then you make it fast. Hopefully this presentation has helped provide you some useful techniques for making it fast.
If I appear to be some kind of optimization guru, remember that appearances are often deceiving.
I am a programmer just like most of you. While I have experience working on optimizations, it is still mostly a process of trial and error for me. Many times haved I tried a new optimization approach, only to benchmark it after and discover that I made the performance worse. And that is OK, for I learned that something did not work, adding to my knowledge of approaches to avoid in the future. Then I just reverted the code and tried a different approach.
One great thing about optimization is it is usually easy to see if you succeeded or failed. You can use the benchmark or benchmark-ips libraries and see if your attempt at optimization improved the performance.
If you aren’t sure what part of your code to start optimizing, start by profiling the code. There are more options for this, such as ruby-prof, stackprof, rack-mini-profiler, and rbspy. Profiling allows you to find out what methods are taking the most time, which are usually the best places to start optimizing.
If you haven’t tried to optimize code before, now is a great time to start. Optimization is within your power. You can do it.
For many years, we as a community have made it work.
We have made it correct.
We have made it very fun.
Now, let us all work together to improve the performance of Ruby libraries, and through them the performance of Ruby programs.
Together, let us usher in a new age of Ruby performance. We as a community can do it!
Kore de watashi no happyo wa owaridesu. Watashi no hanashi o kiite kurete arigato. (That concludes my presentation. Thank all of you for listening to me.)
I am sure many of you have questions, so please ask them now. Hazukashi garanaide, shitsumon shite kudasai. (Do not be shy, please ask a question.)
Photo credits
Benchmark Graphs: TechEmpower
Thank You / Arigato : http://img02.deviantart.net/13c6/i/2011/267/7/f/arigato_gozaimasu_by_emmaprew-d4asmyu.jpg
Question Mark: https://pixabay.com/photos/question-mark-knowledge-question-3255118/