
| z, ? | toggle help (this) |
| space, → | next slide |
| shift-space, ← | previous slide |
| d | toggle debug mode |
| ## <ret> | go to slide # |
| r | reload slides |
| n | toggle notes |
Hello everyone. In this presentation, I’m going to talk about redistricting in California, and the systems I built using Ruby to assist California’s redistricting process.
My name is Jeremy Evans. I am a Ruby committer who focuses on fixing bugs in Ruby.

I am also the author of Polished Ruby Programming, which was published last year. This book is aimed at intermediate Ruby programmers and focuses on teaching principles of Ruby programming, as well as trade-offs to consider when making implementation decisions.

First, what is redistricting? In order to answer that question, I’m going to have to give a brief civics lesson.
What is a district? In this context, a district is an area of land where citizens residing on that land vote for a person to represent them.
The United States is a representative democracy with a bicameral legislature known as Congress.
The lower chamber of Congress is the House of Representitives. Each state has a variable number of representatives in the House, based on the state’s population. Representatives in the House are supposed to represent the citizens that are in their particular district, to ensure that each citizen has a local representative in Congress.|These districts, called congressional districts, are an example of the type of district we are discussing. Congressional districts are supposed to be roughly equal in population, to ensure that that each citizen in the United States has roughly equal representation in the House of Representatives.
Because population changes over time, ensuring roughly equal local representation requires modifying district boundries.
The process of modifying districting boundries to account for changes in population is referred to as redistricting.
Historically, the process of modifying the district boundries in California was often performed by elected officials. This allowed the people currently in power to modify district lines in a way to keep themselves in power, which is an obvious conflict of interest.
In 2008, California citizens voted in favor of a proposition to change the redistricting process so that it was performed by an independent group of citizens.
This group is named the Citizens Redistricting Commission.|Using an independent group of citizens to perform the redistricting avoids the conflict of interest issues that previously existed. However, how could the citizens of California be sure that the members of the Citizens Redistricting Commission would be the most qualified citizens to perform the redistricting work?
The responsibility for soliciting applications to be a member of the Citizens Redistricting Commission, as well as determining the most qualified candidates, was given to the California State Auditor.

This is how I became involved in the process. At the time the 2008 redistricting proposition was passed, I was the sole programmer and lead systems administrator at the California State Auditor’s office.|In July 2009, with less than 5 months until launch, the team handling the redistricting project requested that I develop an automated system to handle accepting and reviewing applications to be a member of the Citizens Redistricting Commission.
Now that you have the background, the rest of this presentation will focus on the design and implementation of the systems I built to handle the application process for redistricting commissioners.
We’ll start with the design and implementation of the system for the 2010 redistricting process.
Naturally, the first part of any system design is to gather requirements. In terms of initial requirements, beyond the basic authentication requirements most systems have,
the most important part of the system is the ability for the system to accept applications to be a member of the commission. There are actually two applications, an initial application that takes about 5 minutes to fill out, and a supplemental application with four essay questions and the requirement to list all close family members, previous addresses, large financial contributions and a full employment, education, and criminal history.|The supplemental application took most applicants many hours to complete. Only about 10% of the citizens who submitted an initial application also submitted a supplemental application.
All applications have to be reviewed by our staff to make sure they don’t contain any information that is offensive or confidential.
All qualified applications received are posted publicly for all citizens to review, to ensure transparency during the selection process.
An audit log is kept of all basic changes made in the system, with the ability for administrators to search and review the logs. The audit logging feature ended up being critically important during the process.|One of the most important lessons I learned during the 2010 redistricting process was the importance of audit logging. All production systems I design and maintain now have at least a basic audit log showing changes made via the system.
The initial design used 3 separate systems for handling the first three requirements.
There was a system called the public system that allowed citizens to login and submit applications.
There was a system called the internal system that allowed our staff to login and review the applications. Access the internal system required being physically present at our office, it was not accessible from the Internet.
I assumed when designing the system that 99% of the web requests would be for the public viewing the applications. Since viewing the applications did not require login, and applications could not generally be modified after being submitted, I decided the easiest approach would be generating a static site for viewing the applications, so the third system was the static site generator.
Given the limited time until launch and a budget of zero, I decided to run the system on our existing infrastructure.
That infrastructure consisted of single server that we bought in 2002. This server had dual 1.4 GHz Pentium III CPUs, a single gigabyte of RAM, and an 18GB 10,000 RPM hard drive. This server already ran other internal applications, so not all of the RAM was available for the redistricting system to use.
The server ran OpenBSD and used PostgreSQL as the database and Ruby as the programming language for the existing applications.
One on the first decisions I had to make when starting to develop the application was what libraries I would use to build this, starting with the library for database access.
By mid 2009, I had already been maintaining Sequel for over a year, and all internal development had already switched to Sequel, so Sequel was the natural choice. I added a nested_attributes plugin to Sequel at the start of this process, which I used to handle the system’s supplemental application.
Then I had to decide on which web framework to use. At the time, the other production applications I maintained used Rails. However, by 2009, I had already become disenchanted with Rails.|As I mentioned, there were separate public, internal, and static site applications, which all use the same models, which is something Rails still doesn’t support well.
I had some experience developing personal projects with Sinatra, and saw how much faster it was to develop applications in Sinatra, as well as how Sinatra was faster at runtime, so I decided to use Sinatra as the web framework for all systems.
In terms of authentication, there wasn’t a good authentication library at the time development started.
So I designed a custom authentication system.
Like most applications, we had a need for a job system to reduce the amount of time spent during web requests.
Unlike most applications, we used standard unix cron for this purpose. Most of the jobs we had were not very time sensitive, with our most frequent jobs running every 5 minutes.
In terms of testing, due to the limited time I had for systems development, I decided to only perform integration testing, and skip model testing completely.
I also did not perform any coverage testing during the 2010 redistricting process.
To make submission of the supplemental application easier, the supplemental application used JavaScript if available. However, no part of the applications required JavaScript. The integration tests didn’t use JavaScript, and still passed.
We did not do any automated testing of the JavaScript, all JavaScript testing was performed manually.
Before launching the system, in order to ensure the system could handle the expected load, we performed some end-to-end load testing.
Remember when I discussed the infrastructure, with the single server with the dual core Pentium III? During the end-to-end load testing, I found that we could process about 1 supplemental application per second per CPU, for a total
of 2 applications per second. That sounds really bad, right? You cannot possibly report numbers that low. So I told the project manager that we could handle
120 applications per minute. That’s a much more respectable number, and the project manager agreed that we would be fine using the existing infrastructure.
We only received around 4800 total supplemental applications during the 2010 redistricting process, and the existing infrastructure did work fine.
Here’s what the initial application looked like in 2010. As you can see, we did not spend anything on visual design. I was kind of suprised that they didn’t have our visual design team make this look prettier, but the project manager told me that he liked that it was obvious to stakeholders that we did not waste any of our budget on visual design.
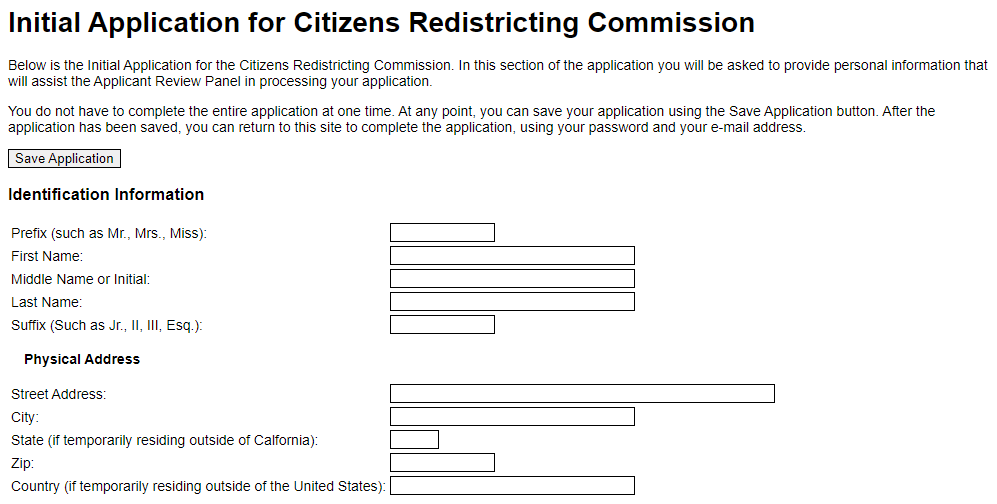
When the 2010 systems launched, the systems had 44 routes.
By the end of the 2010 redistricting process, the systems had 132 routes, 3 times the number of routes the systems had at launch.
Between system launch and the end of the process, there were 30 database migrations, many of which implemented entirely new subsystems in the application.|When we launched, we did not know how big the system actually needed to be. There were many subsystems we did not anticipate needing an automated system for when we launched. Let me give some examples.
When we launched, we had no idea how many full applications we would receive. We ended up receiving many more than expected, and we needed to build a system to review supplemental applications to determine which were the most qualified.
When we launched, we knew we would have to receive public comment on applications. However, we didn’t know what form such public comments would take. We had to build a system to accept, review, and post public comments.
Then we determined we needed a system so that applicants could respond to those public comments, and for us to review and post their responses.
There was an appeals process for applicants who were disqualified, and enough applicants requested reconsideration of their applications that we had to design a system for that.
People, being human, make mistakes. As it turns out, a lot of mistakes. We had to build a system to handle submitting, reviewing, and posting amendments to applications.
The redistricting team and I used a just in time development approach. As soon as the team hit a bottleneck, and needed something automated, they would contact me and I’d develop a system to handle it, usually with 1 or 2 days between request and production deployment.
In general, the 2010 redistricting system was considered a huge success for a government IT project, especially one that basically had zero budget.|While the 2010 system was a success, and I still consider it a major accomplishment given the constraints, the just in time development approach resulted in system developed in an ad-hoc manner.
So when it came time to develop the 2020 system, I considered the 2010 system a prototype. For one, the 2010 system was not maintained after the 2010 redistricting process ended.
In most of my system designs, I use an evolutionary prototype approach, constantly refining the prototype until it becomes fully production ready. That’s because I am usually not time constrained when developing prototypes.
This is one case I decided to throwaway the prototype, and develop a completely new system. We didn’t throwaway the prototype completely, as we did keep it for reference, but the 2020 system shared no code with the 2010 system.
In mid 2018, I started designing the 2020 system. The 2020 system would handle everything that the 2010 system handled. In addition, it would automate some additional tasks not automated in 2010.
One new feature in the 2020 system was much more extensive audit logging. Instead of just logging what type of change was made, the 2020 audit log kept previous values for all changed columns.|Administrators could view the basic audit log, and drill down for any entry to see the previous column values for all rows updated in the same transaction. This feature was implemented using database triggers and a jsonb column to store the previous values.
Another improvement was a change in which demographic options the applications supported. The system recorded and displayed demographic information for all applicants as required by law. In 2010, there were only 2 options for gender and 7 options for ethnicity. In 2020, system had 3 options for gender and 23 options for ethnicity.
When designing the 2020 system, I had the expectation up front that it would not be a prototype. I designed the 2020 system with the expectation that it would be continuously maintained after the 2020 redistricting process, and eventually used for the 2030 and future redistricting processes.
In terms of of the 2020 system design,
The operating system, database, and language were the same as the 2010 system, just newer versions of each.
Sequel was still the natural choice for database access.
The 2010 system used Sinatra. I ended up using Sinatra for all new systems development between 2009 and 2013, while still maintaining older applications developed in Rails.|One issue I ended up having with all of my Sinatra applications, is that many of the routes would have duplicated code, since Sinatra didn’t and still doesn’t have good support for sharing code on a per-routing branch basis. I still preferred Sinatra to Rails, as in general my Sinatra applications were easier to maintain and understand.
To address the issues I had with Sinatra, I created Roda in 2014.|One advantage of Roda is that you can more easily share code between routing branches, resulting in code that is even easier to maintain than Sinatra. Roda was used as the web framework for the 2020 redistricting system.
In 2015, I had a bunch of applications that all used custom authentication designs, using a more secure approach than most applications, where the database user the application used did not have direct access to the password hashes.|There wasn’t an existing authentication library that supported this approach, and the only Ruby authentication libraries that existed required Rails.
In 2015, I designed a new authentication library named Rodauth that used this more secure approach. Rodauth was used for authentication in the 2020 system.|Rodauth is now Ruby’s most advanced authentication library. It is built on top of Sequel and Roda, but it is usable as Rack middleware to handle authentication for any Ruby web application.
One of the big problems we had during the 2010 process was that users could not remember their passwords. So the project lead wanted to default to a passwordless authentication system in the 2020 system. Early on during development of the 2020 system, I added a feature to Rodauth to support passwordless authentication using email. Users could still choose to create a password if they wanted to.
To increase the security of the internal systems, at the application level, two factor authentication was used, with a password and TOTP required for access to the internal systems.|There was an additional authentication factor needed for access to internal systems, so the internal systems in total had three factor authentication. I’ll discuss the third factor in a bit when I go over the system’s advanced security features.
The use of cron as a job system worked well for the 2010 system, so we again used it for the 2020 system.
We had about twice as much time to develop the 2020 system, starting about 9 months before launch. In addition there were 2 programmers working on the system, not just me. Due to libraries such as Roda and Rodauth in the 2020 system, development of features was faster.
As we had sufficient time, I had a goal of 100% line coverage for the 2020 system. We tested coverage on a regular basis, adding any tests needed to get to 100% coverage.
One process we undertook for the 2020 system that we did not undertake for the 2010 system was having the system accessibility tested by an external vendor. This vendor found many accessibility issues.|It was very interesting to me to work side-by-side with one of the accessibility testers, who was blind and filing out the applications using an iPhone with text-to-speech. I got to see first hand how accessibility issues made filling out the application more difficult.|Pretty much all of the accessibility issues were easy to fix, and we were able to ensure that blind and low vision users were both able to successfully complete the application process using the system.
Here’s what the initial application looked like in 2020. It does look slightly nicer than it did in 2010, since we were provided a couple of graphics for the top. However, the rest of the visual design remained very plain, just black and white, and still had a just-the-facts vibe.
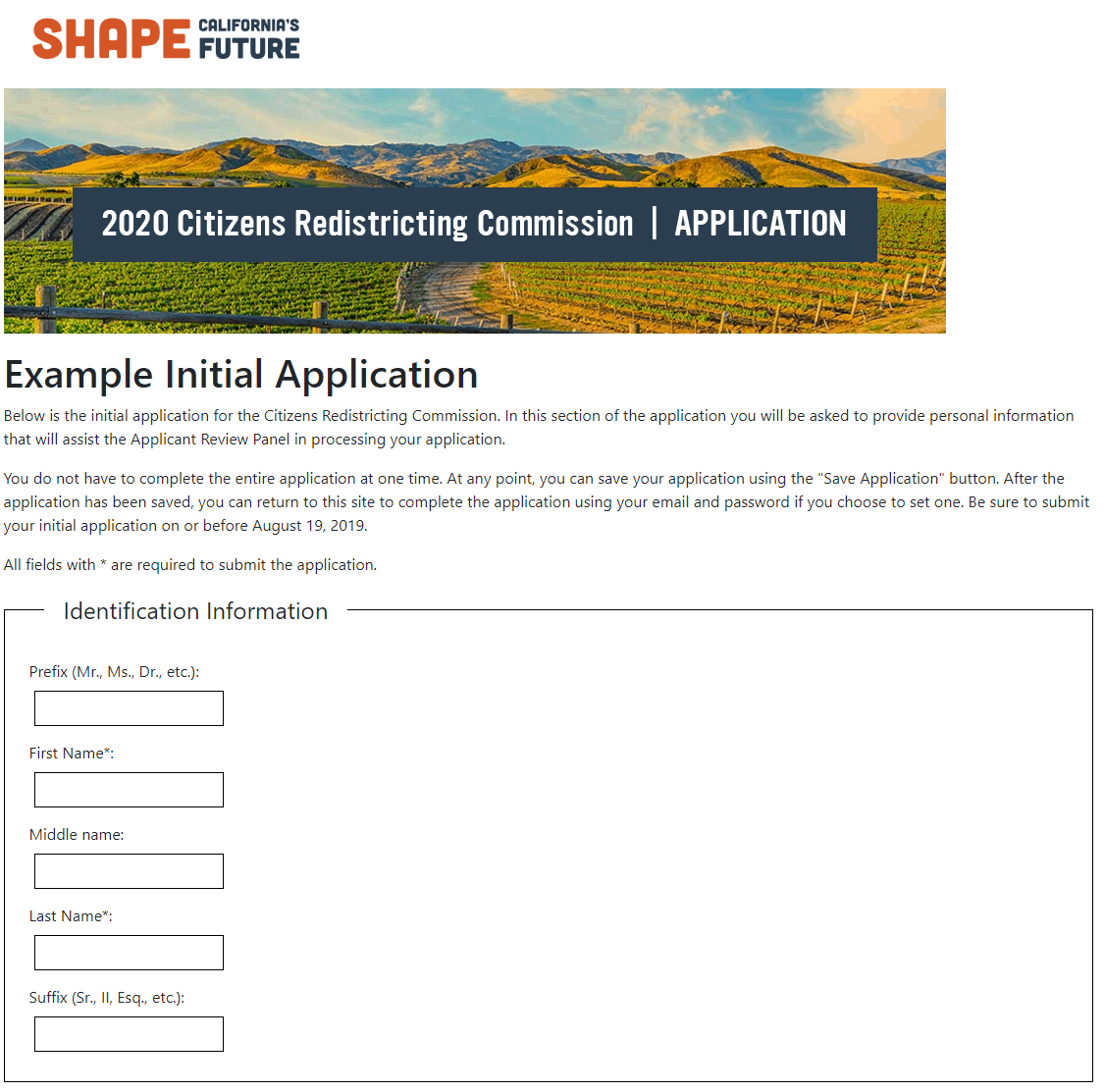
At launch, the 2020 systems had 167 routes. This doesn’t count any routes related to authentication, as those were handled by Rodauth.
At the end of the 2020 redistricting process, the systems had 181 routes, less than 10% more than it had at start. Quite different from the 3x increase in routes that we had during the 2010 process.
During the 2020 process, there were 9 database migrations, most of which were small, and none of which added any new subsystems. The most significant changes were focused on decreasing the time it took to review applications, public comments, and other things the system dealt with.
The most significant change in the 2020 system design was a focus on security. During the 2010 system design, the focus was on getting something that worked. When I met with the project lead for the 2020 system, he specifically tasked me with making the system as secure as I could possibly make it.
So the 2020 system contained many security features that you do not see in typical Ruby web applications.
One of the largest changes is that the internal system was split into separate applications based on what type of database access was needed. In addition, separate operating system users were used depending on how much access the process needed to the file system.
There were actually 12 separate processes used in the 2020 system.
There was still a public system that was used by citizens to submit applications, public comments, and other things. However, in 2020 this system is locked down. For example, the database user for this process could create new applications and public comments, but it could not modify existing ones.
There was a staff system for staff performing the initial review of applications, flagging applications that needed higher-level review.
There was a public comment system for staff performing review of public comments, which require additional scrunity as they are often antagonistic.
There was an administrative system for higher level staff to manage users and perform secondary reviews of applications and public comments flagged during initial reviews.
There was a single system supporting file uploads. No other system supported uploading files. For security, we did not accept uploaded files from the public. Some other internal systems could manage files that had been uploaded via the upload system.
There was a system to handle removing applicants. This was the most sensitive system, which only a couple staff had access to.
The staff that reviewed applications to determine which were most qualified were called ARP members, ARP being short for Applicant Review Panel. By law, there were 3 ARP members, and none of them were allowed to see what the other ARP members were working on. They could only have discussions about applicants during public meetings. So each ARP member had their own system, and the database user for each system only allowed access to their own reviews, it did not allow any access to the reviews by other ARP members.
All ARP Members had an assistant who assisted them with their reviews. These people, referred to as ARP helpers, had less access than ARP members. They could add notes on applications that were viewable to the ARP member they were assisting, but could not modify the ARP member’s decision in the system.|In addition to these systems, there was also a static site generator, since the 2020 system used basically the same static site approach as the 2010 system to allow the public to view submitted applications.
With the exception of the public and upload systems, each of the other systems was only accessible on a per-system specific VLAN.
For example, to access the public comment system, there was only a single workstation connected to the public comment VLAN, so you had to physically be at that workstation in order to access the public comment system. Each of the VLANs were isolated and had no internet access. The only way to access the internal systems was to have physical access to specific workstations inside our office. Access to those workstations was limited to specific staff via physical access cards.
I mentioned earlier that Rodauth was used with two factor authentication in the application, requiring both password and TOTP code to login.
By separating all parts of the system into their own VLANs, each requiring their own access card, all internal systems had three factor authentication, with the third factor being access to a specific physical location.
I mentioned earlier that each of the 12 systems used separate database users with reduced privileges. In some cases, systems needed limited access to tables recorded by other systems, but could not have full access to the tables.
The systems used security definer database functions to make changes not allowed by their database permissions. For example, no internal system was allowed to modify the contents of a submitted application. However, if applicants made a mistake when submitting their applications, they could request their application be unsubmitted so it could be fixed. For this case, there was a security definer database function that modified the application to unsubmit it.
All of the systems were restricted by both ingress, egress, and loopback firewall rules. Most systems were completely isolated and had no internet access at all. The public system was limited to receiving HTTPS connections from 2 front end web servers located in one of the State’s data centers.
To mitigate arbitrary file access and remote code execution vulnerabilities, all systems ran chrooted. The applications started as root, and after they were loaded, but before accepting connections, they chroot to the working directory of the application, then drop privileges to the application’s operating system user. File system permissions were used inside the folder so that attackers could not read configuration files containing sensitive information.
To make exploitation more difficult and to reduce the kernel attack surface for privilege escalation, all systems limited the set of allowed kernel system calls to the minimum the system needed to function, using an OpenBSD specific API called pledge.|After the systems are initialized, none of the systems are allowed to fork, exec, or send signals to other processes. If the system did not need to accept or manage uploaded files, it was not allowed to create or modify any files.
To make it more difficult to execute blind return oriented programming attacks that are based on exploiting consistent memory layouts, each process handling requests would use exec after forking and before loading the system, so that all processes have unique memory layouts.|This has a fairly high memory cost, but we were still able to do this and remain within our memory budget.
In the 2020 process, I requested a budget for a new server so I could run the systems on isolated hardware. This server was fairly modest by the standards of the time, with a 2.1GHz 8-core processor and only 8GB of RAM. Importantly, it had an RAID-1 of solid state disks for storage.
If you remember, the 2010 system could only process about 120 supplemental applications per minute.
Due to more modern hardware, newer Ruby and PostgreSQL versions, and more optimized Ruby libraries, the 2020 system could process 7200 supplemental applications per minute.
This proved to be more than sufficient, considering we only received 2200 total supplemental applications during the 2020 redistricting process.
I mentioned earlier that I aimed for 100% line coverage in the 2020 system, and we did meet that. However, while less than 100% coverage means something, 100% coverage means nothing.
In particular, 100% coverage does not mean that you have no bugs.
During the 2020 redistricting process, we had 43 unhandled exceptions, with the majority in the public system.
19 of these exceptions were traced to 5 separate race conditions. In all cases, these race conditions were caught by database constraints.
19 of these exceptions were due to form submissions with invalid child associations, in cases where Sequel’s nested_attributes support hadn’t yet supported handling the invalid association automatically
3 of the exceptions were due to ASCII NUL being included in form submissions during login.
2 of the exceptions were due to a deployment issue.
All told, the 2020 redistricting process was much smoother than the 2010 process. That’s mostly because we knew what to expect, and in general anticipated it and planned for it. However, during the process the team noticed many possibilities for improving the process. In critical cases, we made changes to the 2020 system, but in the majority of cases, we decided to delay improvements until the 2030 system.
Shortly after the end of the 2020 process, we had a series of meetings discussing various possible changes to the system for 2030. Before the end of 2020, I already started making some internal changes to fix the unhandled exceptions that occurred during 2020 process.
I added support to Sequel’s nested_attributes plugin to handle the issues exposed during the 2020 process, so they would not raise exceptions.
To handle the race conditions experienced during the 2020 process, I added a code injection framework, so I could simulate race conditions during the tests, and then made changes to avoid the race conditions. In addition to fixing the 5 race conditions that resulted in exceptions during the 2020 process, I audited all other routes for similar race conditions, and found an additional race condition that was not hit, which I also fixed.
To prevent the unhandled exceptions due to ASCII NUL bytes, I modified Rodauth to handle this case. I also added similar handling in Roda and Sequel.
My goal in the 2030 system is to have 100% line and branch coverage.
We started off with 100 uncovered branches. Over a two week period, we covered all 100 branches,
finding and fixing 4 previously undetected bugs in the uncovered branches. I’ll state again for emphesis, 100% line/branch coverage means nothing, but less than 100% means something.
Another goals for 2030, which has not yet been implemented, is to get to 100% line/branch coverage for all views in the system.
The 2020 system used chroot and privilege dropping to limit file system access to the application directory.
For the 2030 system, I switched to using unveil, which is an OpenBSD-specific API for more granular file system access limiting. This made it so only a small portion of the application directory was accessible at runtime, instead of all of the application directory being accessible. Additionally, switching to unveil made it so the application did not need to be started as root, so privilege dropping was not needed.
By continuing to maintain and improve on the 2020 system, I think the 2030 system will be just as much of a success.
I hope you had fun learning about redistricting in California, and how Ruby has helped the redistricting process in the past and will continue to help the redistricting process in the future.
If you enjoyed this presentation, and want to read more of my thoughts on Ruby programming, please consider picking up a copy of Polished Ruby Programming.
That concludes my presentation. I would like to thank all of you for listening to me. I think I am out of time, so if you have any questions, please ask me during the next break.